AMD در اقدامی تاریخی با ترکیب معماریهای CDNA 3 و Zen 4، پردازندهای پرقدرت برای سرور میسازد
AMD در جریان برگزاری کنفرانس جدید خود افزونبر بهروزرسانی نقشهی راه پردازندههای مرکزی مبتنیبر معماری Zen و پردازندههای گرافیکی مبتنیبر معماری RDNA، جزئیات بیشتری دربارهی معماری CDNA که به گرافیکهای کلاس سرور اختصاص دارد، ارائه داده است. ای ام دی محصولات سری Instinct را برپایهی این نوع معماری تولید میکند.
AMD برای دو سال آیندهی پردازندههای مرکزی و پردازندههای گرافیکی مخصوص مشتریان عادی مسیری نسبتاً سرراست طراحی کرده، بااینحال قصد دارد پردازندههای گرافیکی کلاس سرور را به شکلی عمده دستخوش تغییر کند.
براساس آنچه AnandTech مینویسد AMD پس از معماری گرافیکی CDNA 2 که در شتابدهندههای سری Instinct MI200 استفاده شدهاند سراغ معماری جدید CDNA 3 خواهد رفت. تیم قرمز در نقشهی راه تمامی محصولات جدیدش تا دو سال آینده را پوشش داد، بااینحال در نقشهی راه مربوط به معماری CDNA 3 شاهد چنین موضوعی نیستیم. AMD در نقشهی راه CDNA به محصولات سال ۲۰۲۳ اشاره کرده است. این شرکت سال آینده نسل جدید معماری گرافیکی کلاس سرور را دردسترس قرار میدهد.

AMD معمولاً در کنفرانس Financial Analysts Day جزئیات زیادی دربارهی محصولاتش ارائه نمیدهد و این موضوع را بهطور مشخص در نقشهی راه نسل جدید معماری Zen و RDNA مشاهده کردیم. بااینحال تیم قرمز در رابطه با CDNA رویکرد نسبتاً متفاوتی در پیش گرفته و جزئیات متعددی شامل ویژگیهای معماری و اطلاعات اولیه منتشر کرده است. AMD حتی گفته در سال آینده نوعی APU جدید عرضه میکند که مبتنیبر معماری CDNA 3 است و از ترکیب چیپلتهای CPU و GPU به دست میآید.
براساس اطلاعات رسمی، پردازندههای گرافیکی مبتنیبر معماری CDNA 3 با استفاده از لیتوگرافی پنج نانومتری تولید میشوند. AMD همچون شتابدهندههای سری MI200 (مبتنیبر CDNA 2)، در نسل جدید شتابدهندههای خود نیز از طراحی چیپلت برای ترکیب حافظه، کش و هستههای پردازشی روی یک تراشه استفاده خواهد کرد.
جالب است که AMD این طراحی را «چیپلت سهبعدی» خطاب میکند. این یعنی در پردازندههای مبتنیبر معماری CDNA 3 نهتنها هر چیپلت با چیپلتهای کناری ارتباط برقرار میکند بلکه شماری از چیپلتها در قالب یک بستهی بههممتصل روی هم قرار میگیرند و با هم ارتباط برقرار میکنند؛ مثل روش V-Cache در پردازندههای مرکزی Zen ۳.
شاید مقایسهی CDNA با Zen در نگاه اول منطقی نباشد، اما هرچه زمان میگذرد چنین مقایسهای پراهمیتتر میشود؛ چون AMD میگوید بهدنبال اضافه کردن فناوری Infinity Cache به معماری CDNA 3 است. همچون مثالی که برای V-Cache زدیم، با استناد بر اسلایدهای منتشرشده توسط AMD میتوانیم بگوییم تیم قرمز میخواهد کشهای نوع اینفینیتی را با برد منطقی بهعنوان واحدهای جداگانه روی هم قرار دهد؛ این در حالی است که در پردازندههای گرافیکی کلاس دسکتاپ و لپ تاپ، این واحدها در قالب یک Die یکپارچه استفاده میشوند.
بهخاطر سبک طراحی جدید، چیپلتهای Infinity Cache معماری CDNA 3 در زیر چیپلتهای پردازشی تعبیه میشوند. بهنظر میرسد AMD برای خنک نگهداشتن چیپلتهای منطقی پرقدرت و پرمصرف، قصد دارد آنها را در بالاترین بخش دستهی چیپلتها قرار دهد.

به گفتهی AMD محصولات خانوادهی CDNA 3 قرار است مبتنیبر چهارمین نسل از معماری Infinity (موسوم به IA4) باشند. درحالحاضر جزئیات خیلی زیادی دربارهی این معماری اعلام نشده، اما بهنظر میرسد IA4 در همکاری با چیپلتها قرار است تحولات قابلتوجهی در پردازندههای گرافیکی AMD اعمال کند.
بهلطف نسخهی چهارم، بستههای دو و نیم بعدی و سه بعدی تراشه میتوانند از معماری Infinity استفاده کنند؛ به بیانی بهتر، تمامی تراشههای حاضر در بسته به سابسیستم حافظهی منسجم و کاملاً یکپارچه دسترسی پیدا خواهند کرد. این یکی از بزرگترین تغییرات IA4 نسبت به IA3 است.
در شتابدهندههای سری MI200 که از IA3 استفاده شده، تراشهها به سابسیستم یکپارچه دسترسی ندارند. شتابدهندههای MI200 اساسا مثل دو پردازندهی جداگانه روی یک زیرلایه فعالیت میکنند، اما IA4 به شتابدهندههای MI300 امکان میدهد مثل تراشهای واحد فعالیت کنند، آن هم با وجود جدا بودن چیپلتها از یکدیگر.
AMD در اسلایدهایش اعلام کرده است باری دیگر سراغ استفاده از حافظهی HBM میرود. البته فعلاً به نسخهی مورد استفاده از حافظهی HBM اشاره نشده، اما با در نظر گرفتن عرضهی تراشههای مبتنیبر CDNA 3 در سال ۲۰۲۳ پیشبینی میکنیم این تراشهها از HBM 3 استفاده کنند.
AMD افزونبر این موارد قصد دارد سرعت پردازش تسکهای هوش مصنوعی را در نسل جدید شتابدهندههایش بالا ببرد. AMD میگوید در نسل جدید شتابدهندههایش از فرمتهای ترکیبی جدیدی پشتیبانی خواهد کرد. تیم قرمز جزئیات فنی را اعلام نکرده اما میگوید معماری CDNA 3 در زمینهی عملکرد به ازای وات در وظایف هوش مصنوعی بیش از پنج برابر بهبود پیدا میکند.
این موضوع بهطور غیرمستقیم نشان میدهد AMD در حال بازسازی عمدهی هستههای ماتریکس در معماری جدید CDNA است، چون بهبود پنج برابری بسیار بیشتر از آن چیزی است که استفاده از لیتوگرافی جدید امکانپذیر میکند.
AMD برای محصولات کلاس سرور برنامههای بزرگی در سر میپروراند. این شرکت اکنون هستههای پرقدرت CPU و GPU را دردسترس دارد و در تلاش است افزونبر بهبود قدرت، این هستهها را با هم ترکیب کند. با ترکیب هستههای CPU و GPU، تیم قرمز موفق به تولید APU ردهبالایی در حوزهی دیتاسنتر خواهد شد. تولید این APU دستاورد بسیار مهمی است.

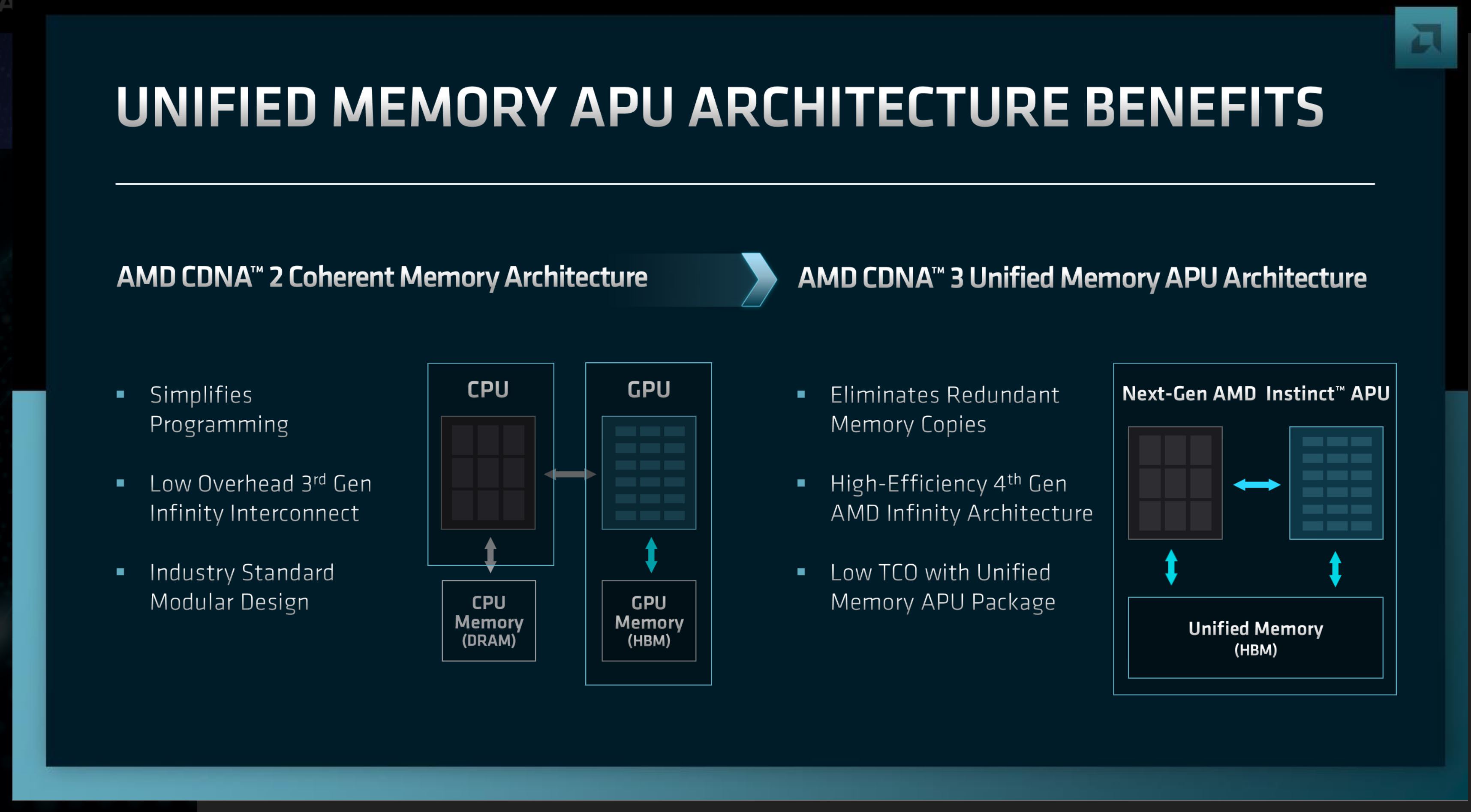
APU جدید شرکت AMD که فعلا با کدنام MI300 شناخته میشود از مدتها پیش مراحل تولید را میگذارند. معماری IA3 به AMD امکان داد محصولات خانوادهی MI200 را با ترکیبی از هستههای CPU و GPU تولید کند و حافظهای منسجم دردسترس آنها قرار دهد و بهلطف IA4 ترکیب CPU و GPU عمیقتر از قبل انجام خواهد گرفت.
استفاده از معماری یکپارچه مزایایی برای محصولات سری MI300 به همراه خواهد آورد. یکی از اصلیترین مزایا، بهبود عملکرد خواهد بود. در این سبک طراحی جدید، پردازندهها برای دسترسی یا ویرایش دادهها مجبور نیستند آنها را در حافظهی اختصاصی خود کپی کنند. استفاده از مخزن یکپارچهی حافظه بدین معنی است که پردازندههای جدید نیازی به مجموعهی ثانویهای از تراشههای حافظه ندارند.
مقالههای مرتبط:
در محصولات خانوادهی MI300 چیپلتهای گرافیکی CDNA 3 و چیپلتهای Zen 4 در قالب پردازندهای واحد با هم ترکیب میشوند و هر دو این چیپلتها حافظهی HBM را به اشتراک خواهند گذاشت. فرض ما بر این است که چیپلتها Infinity Cache را نیز به اشتراک بگذارند.
هستههای CPU، هستههای GPU، واحدهای HBM و البته Infinity Cache همگی چیپلتهای متفاوتی هستند و AMD در پی متصل کردن آنها به یکدیگر است. این یعنی تیم قرمز روی تراشهای کار میکند که تاکنون سابقهی تولید آن را نداشته است. محصولات خانوادهی MI300 نشاندهندهی جدیترین تلاش AMD برای استفاده از چیپلت خواهند بود.
AMD بهطور واضح میگوید که قصد دارد در زمینهی پهنای باند حافظه و تأخیر در پردازش رهبر بازار باشد. در صورت عملی شدن این هدف، شاهد دستاورد بزرگی برای AMD خواهیم بود. فراموش نکنید AMD اولین شرکتی نیست که به استفاده از HBM در هستههای CPU علاقهمند شده؛ اینتل هماکنون روی محصولات خانوادهی Sapphire Rapids با رویکرد مشابه کار میکند.
AMD میگوید APU جدیدش میتواند در مقایسه با MI250X تعلیم مدلهای یادگیری ماشین و هوش مصنوعی را بیش از هشت برابر سریعتر انجام دهد. همین ادعا باری دیگر ذهن ما را به سمت اصلاح هستههای ماتریکس میبرد.
