هر آنچه باید دربارهی یادگیری ماشین و کاربردهای آن بدانیم

هوش مصنوعی (AI) همه جا حضور دارد. ممکن است همین حالا در حال استفاده از آن باشید و خود اطلاعی نداشته باشید. یکی از محبوبترین کاربردهای AI در زمینهی توسعهی نرمافزار سفارشی، یادگیری ماشین (ML) است. کامپیوترها، نرمافزارها و دستگاههای یادگیری ماشین عملکردی مشابه مغز انسان دارند و از طریق شناخت وظایف را انجام میدهند.
یادگیری ماشین به کامپیوترها اجازه میدهد وظایف انسانها را انجام بدهند. یادگیری ماشین با انجام وظایفی مثل هدایت خودرو یا ترجمهی گفتار، انقلابی در زمینهی هوش مصنوعی به وجود میآورد و به نرمافزارها در درک دنیای واقعی بینظم و غیر قابل پیشبینی کمک میکند؛ اما یادگیری ماشین دقیقا چیست و چه کاربردهایی دارد؟ در این مقاله پاسخ جامعی به این پرسش خواهیم داد.
یادگیری ماشین چیست
بر اساس تعریفی دقیق، یادگیری ماشین شاخهای از هوش مصنوعی (AI) متمرکز بر ساخت برنامههایی است که از دادههای یاد میگیرند و دقت آنها به مرور زمان و بدون نیاز به برنامهنویس افزایش مییابد. در علوم دادهای، الگوریتم شامل یک توالی از مراحل پردازش آماری است. در یادگیری ماشین، الگوریتمها برای یافتن الگوها و مشخصات در مقادیر انبوه دادهها آموزش داده میشود تا بتوانند تصمیمها و پیشبینیهایی را بر اساس دادههای جدید اتخاذ کنند. هرچقدر الگوریتمی بهتر باشد، تصمیمها و پیشبینیهای خروجی دقیقتر خواهند بود.
پیشبینیهای یادگیری ماشین میتواند شامل پاسخ به پرسشهایی مثل تشخیص یک میوه در تصویر، تشخیص افراد در حال عبور از خیابان، تشخیص گفتار دقیق برای تولید کپشنهای ویدئوی یوتیوب یا تفکیک ایمیل و اسپم باشد. تفاوت کلیدی یادگیری ماشین با نرمافزار کامپیوتری قدیمی این است که توسعهدهندهی انسانی کد یادگیری ماشین را نمینویسد. بلکه مدل یادگیری ماشین چگونگی تفکیک بین عناصر در مجموعهی انبوهی از دادهها را فرامیگیرد. کلید اصلی یادگیری ماشین همان مقدار انبوه دادهها است که امکان یادگیری را برای آن فراهم میکند.
تفاوت هوش مصنوعی و یادگیری ماشین
یادگیری ماشین اخیرا به موفقیت زیادی رسیده است؛ اما فقط یکی از شاخههای هوش مصنوعی است. در ابتدای ظهور هوش مصنوعی در دههی ۱۹۵۰ این تعریف برای آن ارائه شد: هر ماشینی که قادر به اجرای وظایفی است و نیاز به هوش انسانی دارد. هر کدام از سیستمهای هوش مصنوعی دارای یک یا چند عدد از این ویژگیها هستند:
- برنامهریزی
- یادگیری
- استنتاج
- حل مسئله
- ارائهی اطلاعات
- درک
- حرکت
- دستکاری اطلاعات
- هوش اجتماعی و خلاقیت
در کنار یادگیری ماشین، روشهای متعدد دیگری برای ساخت سیستمهای هوش مصنوعی وجود دارند از جمله این روشها میتوان به محاسبات تکاملی اشاره کرد که در آن الگوریتمها دستخوش جهشهای تصادفی میشوند و برای راهحلهای بهینه به تکامل میرسانند. نوع دیگر هوش مصنوعی سیستمهای خبره هستند. در سیستمهای خبره، کامپیوترها با قوانینی برنامهنویسی میشوند که امکان تقلید از رفتار انسان در حوزهای مشخص مثل سیستمهای هدایت خودکار هواپیما را میدهند.

از یادگیری ماشین میتوان برای بهبود مراکز دادهای یا دیتاسنترها استفاده کرد
یادگیری ماشین چگونه کار میکند
چهار گام اصلی برای ساخت اپلیکیشن یا مدل یادگیری ماشین وجود دارد. دانشمندان دادهای در همکاری نزدیک با کارشناسان تجاری به توسعهای این مراحل میپردازند:
مرحلهی ۱: انتخاب و آمادهسازی دیتاست آموزشی
دادههای آموزشی به مجموعهی دادهای گفته میشود که نمایندهی مدل یادگیری ماشین است و برای حل مسائلی مشخص به کار میرود. در برخی نمونهها، دادههای یادگیری از نوع برچسبدار هستند تا ویژگیها و طبقهبندیهایی را برای مدل فراخوانی کنند. دادههای دیگر از نوع بدون برچسب هستند در این شرایط مدل باید برخی ویژگیها را برای تخصیص طبقهبندیها استخراج کند. در هر دو نمونه دادههای یادگیری باید بهخوبی آماده شوند. فرایند آمادهسازی شامل تصادفیسازی و بررسی انحرافهایی است که بر یادگیری تأثیر میگذارند. دادهها در این مرحله به دو زیرمجموعه تقسیم میشوند: زیرمجموعهی یادگیری که برای آموزش برنامه به کار میرود و زیرمجموعهی تکاملی که برای تست و اصلاح آن به کار برده میشود.
مرحلهی ۲: انتخاب الگوریتمی برای اجرای مجموعه دادههای آموزشی
الگوریتم شامل مجموعهای از مراحل پردازش آماری است. نوع الگوریتم به نوع دادهها (برچسبدار یا بدون برچسب) یا مقدار دادههای موجود در مجموعه دادههای آموزشی و همچنین نوع مسئله وابسته است. انواع متداول الگوریتمهای یادگیری ماشین قابل استفاده با دادههای برچسبدار عبارتاند از:
- الگوریتمهای رگرسیون: رگرسیون خطی و منطقی نمونههایی از الگوریتمهای رگرسیون بهکاررفته برای درک روابط بین دادهها هستند. از رگرسیون خطی برای پیشبینی مقدار متغیر وابسته بر اساس مقدار متغیر مستقل استفاده میشود. از رگرسیون منطقی هم زمانی استفاده میشود که متغیر وابسته ماهیتی دودویی داشته باشد.
- درختهای تصمیم: درختهای تصمیم از دادههای طبقهبندیشده برای ارائهی پیشنهاد بر اساس مجموعهی قوانین تصمیم استفاده میکنند. برای مثال، درخت تصمیمی که شرطبندی روی برد یک اسب را توصیه کند از این دست است.
- الگوریتمهای مبتنی بر نمونه: مثال خوبی از الگوریتمهای مبتنی بر نمونه، الگوریتم K نزدیکترین همسایه یا الگوریتم k-nn است. این الگوریتم از طبقهبندی برای تخمین احتمال وجود نقطهای دادهای در یک گروه استفاده میکند.
- الگوریتمهای دستهبندی: دستهها را همان گروهها تصور کنید. دستهبندی متمرکز بر شناسایی گروههایی با رکوردهای مشابه و برچسبگذاری رکوردها بر اساس گروهی است که به آن تعلق دارند. این کار بدون دانش قبلی دربارهی گروهها یا ویژگیهای آنها انجام میشود. انواع الگوریتمهای دستهبندی عبارتاند از: K-میانگین، دستهبندی دومرحلهای (TwoStep) و دستهبندی کوهونن
- الگوریتمهای رابطهای: الگوریتمهای رابطهای بهدنبال الگوها و روابط در دادهها میروند و روابط تکراری «اگر آنگاه» یا if-then را شناسایی میکنند. این روابط مشابه قوانین بهکاررفته در دادهکاوی هستند.
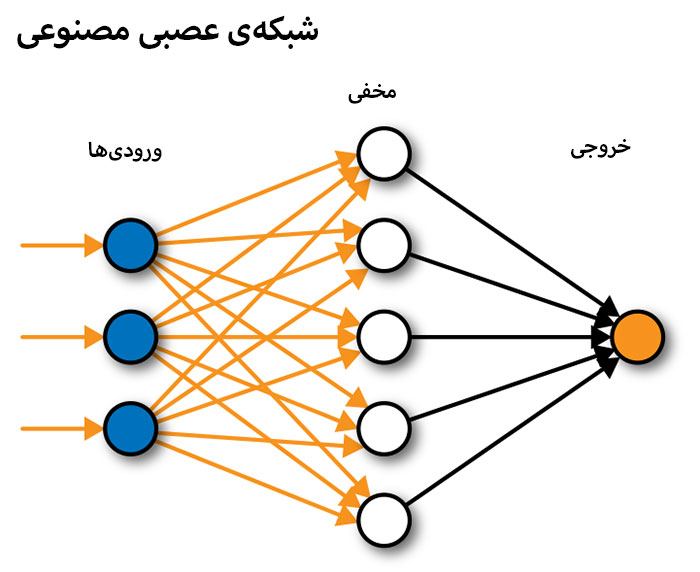
- شبکههای عصبی: شبکهی عصبی، الگوریتمی است که شبکهای لایهبندیشده از محاسبات شامل لایهی ورودی را تعریف میکند. حداقل یک لایهی مخفی وجود دارد که محاسبات آن نتایج متفاوتی دربارهی ورودی دارند و یک لایهی خروجی هم وجود دارد که در آن هر نتیجهگیری به یک احتمال تخصیص مییابد. شبکهی عصبی عمیق، شبکهای با لایههای مخفی متعدد است که هر کدام نتایج لایهی قبلی را پالایش میکنند.
مرحلهی سه: آموزش الگوریتم برای ساخت مدل
آموزش الگوریتم فرآیندی تکراری است. این مرحله شامل اجرای متغیرها در الگوریتم، مقایسهی خروجی با نتایج قابل انتظار، تنظیم وزنها و انحرافهای داخل الگوریتم و راهاندازی مجدد متغیرها است تا زمانیکه الگوریتم نتیجهی صحیح را بازگرداند. الگوریتم آموزشدیدهی حاصل، نوعی مدل یادگیری ماشین است.
مرحلهی ۴: استفاده از مدل و بهبود آن
مرحلهی آخر، استفاده از مدل با دادههای جدید و در بهترین حالت بهبود دقت و کارایی آن به مرور زمان است. منبع دادههای جدید هم به نوع مسئله وابسته است. برای مثال، مدل یادگیری ماشینی که برای شناسایی اسپم طراحی شده است، پیامهای ایمیل را بهعنوان ورودی دریافت میکند درحالیکه مدل یادگیری ماشین که هدایت ربات جاروبرقی را بر عهده دارد دادههای مربوط به تعامل واقعی با اثاث منزل یا اشیای جدید داخل اتاق را بهعنوان ورودی دریافت میکند.
انواع یادگیری ماشین
یادگیری ماشین به دو دستهی اصلی تقسیم میشود: یادگیری نظارتشده و بدون نظارت.
یادگیری نظارتشده
در فرایند آموزش یادگیری نظارتشده، سیستمها در معرض مقادیر زیادی از دادههای برچسبدار مثل تصاویر رقمهای دستنویس قرار میگیرند. سیستم یادگیری نظارتشده با وجود تعداد کافی نمونهها میتواند دستههای پیکسلها و شکلهای مرتبط با هر عدد را شناسایی کند و اعداد دستنویس را شناسایی کند.
بااینحال، آموزش سیستمهای یادگیری ماشین نیازمند تعداد زیادی از برچسبها است بهطوریکه بعضی سیستمها برای مهارت در یک وظیفه به میلیونها برچسب نیاز دارند. در نتیجه دیتاستها یا مجموعههای دادهای بهکاررفته برای آموزش این سیستمها بسیار وسیع هستند. برای مثال دیتاست Open Images گوگل دارای تقریبا ۹ میلیون تصویر است یا YouTube-8M منبعی از ویدئوهای برچسبدار است که به هفت میلیون ویدئوی برچسبدار متصل هستند و ImageNet هم یکی از پایگاه دادههای از این نوع با ۱۴ میلیون تصویر دستهبندی شده است.
اندازهی دیتاستهای آموزشی رو به افزایش است بهطوریکه فیسبوک تقریبا ۳.۵ میلیارد تصویر عمومی اینستاگرام را با استفاده از هشتگهای متصل به هر تصویر بهعنوان برچسب کامپایل کرده است. با یک میلیارد عدد از این تصاویر برای آموزش سیستم تشخیص تصویر، سطح دقت ۸۵.۴ بر اساس شاخص ImageNet به دست آمد.
فرایند طاقتفرسای برچسبگذاری دیتاستهای بهکاررفته در آموزش یادگیری ماشین اغلب با استفاده از سرویسهای کار انبوه مثل Amazon Mechanical Turk انجام میشود که امکان دسترسی به منبع بزرگی از نیروی کار کمهزینه را در سراسر جهان میدهند. برای مثال ImageNet در طول دو سال از پنجاه هزار نفر کمک گرفت که از طریق Amazon Mechanical Turk استخدام کرده بود. بااینحال روش فیسبوک شامل استفاده از دادههای عمومی برای آموزش سیستمها میتواند راهی جایگزین برای آموزش سیستمها با استفاده از دیتاستهای قوی باشد و در این روش نیازی به برچسبگذاری دستی نیست.
یادگیری بدون نظارت
در مقابل، الگوریتمهای یادگیری بدون نظارت با شناسایی الگوهای دادهای تلاش میکنند شباهتهایی را بین آنها پیدا کنند. نمونهای از این روش سیستم دستهبندی Airbnb یا Google News است که امکان گروهبندی استوریهایی با موضوع مشابه را فراهم میکند. الگوریتمهای یادگیری بدون نظارت برای جداسازی انواع مشخصی از دادهها طراحی نشدهاند بلکه صرفا بهدنبال دادههایی دارای شباهت هستند.
یادگیری نیمهنظارتشده
اهمیت مجموعههای بزرگ دادههای برچسبداری برای آموزش یادگیری ماشین به مرور زمان به دلیل ظهور یادگیری نیمهنظارتشده کاهش مییابد. همانطور که از نام یادگیری نیمهنظارتشده پیدا است این روش ترکیبی از یادگیری نظارتشده و بدون نظارت است. یادگیری نیمهنظارتشده به مجموعهی اندکی از دادههای برچسبدار و مجموعهی بزرگی از دادههای بدون برچسب برای آموزش سیستمها وابسته است. از دادههای برچسبدار برای آموزش جزئی مدل یادگیری ماشین استفاده میشود سپس از این مدل برای برچسبگذاری دادههای بدون برچسب استفاده میشود به این فرایند شبه برچسبگذاری میگویند. سپس مدل بر اساس ترکیب حاصل از دادههای شبه برچسبدار و دادههای برچسبدار آموزش داده میشود.
دوام یادگیری نیمهنظارتشده در شبکههای مولد تخاصمی (GAN) بهبودیافته است. این سیستمهای یادگیری ماشین میتوانند از دادههای برچسبدار برای تولید دادههایی کاملا جدید استفاده کنند و سپس از این دادهها دوباره برای مدل یادگیری ماشین استفاده کنند. اگر یادگیری نیمهنظارتشده به اندازهی یادگیری نظارتشده بهینه باشد، دسترسی به مقادیر انبوهی از توان محاسباتی برای موفقیت سیستمهای یادگیری ماشین مهمتر از دسترسی به دیتاستهای عظیم برچسبدار خواهد بود.
یادگیری تقویتی چیست
یادگیری تقویتی نوعی مدل یادگیری ماشین مشابه یادگیری نظارتشده است، اما الگوریتم آن با استفاده از دادههای نمونه آموزش نمیبیند. این مدل در طول فرایند اجرا و از طریق آزمون و خطا آموزش میبیند. یک توالی از خروجیهای موفق برای توسعهی بهترین پیشنهادها یا سیاستهای مربوط به یک مسئلهی مشخص تقویت میشوند.
برای درک بهتر یادگیری تقویتی، شخصی را فرض کنید که برای اولینبار میخواهد یک بازی کامپیوتری قدیمی را اجرا کند. شخص با هیچ کدام از قوانین یا روش کنترل بازی آشنا نیست تا اینکه به مرور با مشاهدهی رابطهی بین دکمهها و اتفاقاتی که روی صفحهی نمایش رخ میدهد به روش بازی پی میبرد و عملکرد او بهبود مییابد.
نمونهای از یادگیری تقویتی، شبکهی Deep Q از دیپ مایند گوگل است که انسان را در مجموعهای از بازیهای ویدئویی قدیمی شکست داده است. این سیستم از پیکسلهای هر بازی تغذیه کرده است و اطلاعات مختلفی مثل فاصلهی بین اشیای روی صفحهی نمایش را دربارهی وضعیت بازی نمایش میدهد. سپس چگونگی اجرای وضعیت بازی و عملکرد آن و ارتباط با امتیازها را شرح میدهد. در طول فرایند تعداد زیادی از چرخههای بازی، سیستم در نهایت مدلی میسازد که بر اساس آن برخی اقدامها امتیاز را تحت شرایطی مشخص به حداکثر میرسانند.

ارزیابی مدلهای یادگیری ماشین
مدل پس از تکمیل با استفاده از دادههای باقیماندهای که در طول آموزش به کار نرفتند، ارزیابی میشود. هنگام آموزش مدل یادگیری ماشین تقریبا ۶۰ درصد از دیتاست برای آموزش به کار برده میشود. بیست درصد دیگر هم برای ارزیابی پیشبینیهای مدل و تنظیم پارامترهای اضافی برای بهینهسازی خروجی مدل به کار میروند. تنظیمات مدل برای بهبود دقت پیشبینی مدل هنگام مواجهه با دادههای جدید طراحی شده است.
شبکهی عصبی و نحوهی آموزش آنها
شبکههای عصبی یکی از مهمترین الگوریتمها در هر دو دستهی یادگیری ماشین نظارتشده و بدون نظارت هستند. این شبکهها اساس بخش زیادی از یادگیری ماشین را تشکیل میدهند از طرفی مدلهای ساده مثل رگرسیون خطی را هم میتوان برای پیشبینی بر اساس تعداد کمی از دادهها به کار برد. شبکههای عصبی برای کار با دادههای بزرگی که خصوصیات زیادی دارند، مفید هستند. شبکههای عصبی که ساختار آنها با الهام از مغز انسان طراحی شده است، مجموعهای از لایههای الگوریتمی به هم متصل به نام نورون هستند که دادهها را به یکدیگر وارد میکنند بهطوریکه خروجی لایهی قبلی بهعنوان ورودی لایهی بعدی عمل میکند.
هر لایه را میتوان مجموعهای از مشخصههای متفاوت از دادههای کلی در نظر گرفت. برای مثال استفاده از یادگیری ماشین برای تشخیص اعداد دستنویس بین ۰ تا ۹ را در نظر بگیرید. لایهی اول در شبکهی عصبی به اندازهگیری تراکم پیکسلهای منفرد در تصویر میپردازد، تصویر دوم قادر به تشخیص شکلهایی مثل خطوط و منحنیها است و لایهی نهایی رقم دستنویس را در گروه ۰ تا ۹ دستهبندی میکند.
شبکه با تغییر تدریجی اولویت دادههایی که بین لایههای شبکه در جریان هستند، قادر به یادگیری پیکسلهای شکل اعداد در طول فرایند آموزش است. هر اتصال بین لایهها دارای یک وزن است که ارزش آن برای تغییر اهمیت اتصال، کاهش یا افزایش مییابد. در انتهای چرخهی یادگیری، سیستم بررسی میکند خروجی نهایی شبکهی عصبی چه مقدار با هدف فاصله دارد. برای مثال آیا شبکه در شناسایی عدد دستنویس ۶ بهبود یافته است؟ برای بستن شکاف بین خروجی واقعی و خروجی مطلوب، سیستم بهصورت معکوس در شبکهی عصبی کار میکند و وزنهای متصل به کل اتصال بین لایهها و همچنین مقدار مرتبط به نام انحراف را تغییر میدهد. این فرایند تکثیر معکوس نامیده میشود.
در نهایت این فرایند روی مقادیر بر اساس وزنها و انحراف اجرا میشود و امکان اجرای وظیفهای مشخص مثل تشخیص اعداد دستنویس را به شبکه میدهد و میتوان گفت شبکه چگونگی اجرای وظیفهای مشخص را فراگرفته است.
یادگیری عمیق و شبکههای عصبی عمیق
به زیرمجموعهی یادگیری ماشین، یادگیری عمیق گفته میشود. در یادگیری عمیق، شبکههای عصبی به شبکههای پراکنده با تعداد زیادی لایه توسعه مییابند که شامل تعداد زیادی واحد هستند؛ این واحدها با استفاده از مقادیر انبوه داده آموزش داده میشوند. شبکههای عصبی عمیق میتوانند قابلیت کامپیوترها برای انجام وظایفی مثل بینایی ماشین و تشخیص گفتار را بهبود بدهند.
انواع مختلفی از شبکههای عصبی با نقاط قوت و نقاط ضعف متفاوتی وجود دارند. شبکههای عصبی بازگشتی مناسب وظایفی مثل پردازش زبانی و تشخیص گفتار هستند درحالیکه شبکههای عصبی پیچشی معمولا در تشخیص تصویر به کار میروند. طراحی شبکههای عصبی هم رو به تکامل است و پژوهشگرها به طرح بهینهتری برای نوع مؤثر شبکهی عصبی به اسم حافظهی کوتاه بلندمدت یا LSTM دست یافتهاند که برای سیستمهای مبتنی بر تقاضا مثل ترجمهی گوگل از سرعت خوبی برخوردار است.
از تکنیک هوش مصنوعی الگوریتمهای تکاملی و فرآیندی به نام تکامل عصبی برای بهینهسازی شبکههای عصبی استفاده میشود. این روش توسط آزمایشگاه Uber AI رونمایی شد که مقالاتی را دربارهی کاربرد الگوریتمهای ژنتیکی برای آموزش شبکههای عصبی برای مسائل یادگیری تقویتی منتشر کرد.
آیا یادگیری ماشین صرفا با شبکههای عصبی پیادهسازی میشود؟
پاسخ به پرسش فوق منفی است. مجموعهای از مدلهای ریاضی وجود دارند که میتوان برای آموزش سیستم و پیشبینیها به کار برد. یک مدل ساده شامل رگرسیون منطقی است درحالیکه از نام آن میتوان برای دستهبندی دادهها برای مثال جداسازی اسپم از غیر اسپم استفاده کرد. هنگام پیادهسازی طبقهبندی دودویی ساده بهراحتی میتوان رگرسیون منطقی را پیادهسازی کرد و میتوان از آن برای برچسبگذاری بیش از دو دستهی دادهها استفاده کرد.
نوع دیگری از مدل متداول، ماشینهای برداری پشتیبان (SVM-ها) هستند که در سطح گستردهای برای دستهبندی دادهها و پیشبینی از طریق رگرسیون به کار میروند. SVM-ها میتوانند دادهها را دستهبندی کنند حتی اگر دادههای ترسیمشده نامنظم شوند و دستهبندیشان دشوار باشد. SVM-ها برای رسیدن به این هدف عملیاتی ریاضی به نام ترفند کرنلی را اجرا میکنند که دادهها را در مقادیر جدید تصویر میکند بهطوریکه بتوان آنها را به دستههایی مجزا تقسیم کرد. انتخاب مدل یادگیری ماشین به معیارهای متعددی مثل اندازه و تعداد مشخصههای موجود در دیتاست وابسته است و هر مدل دارای مزایا و معایبی است.
دلیل موفقیت یادگیری ماشین
با اینکه یادگیری ماشین روش جدیدی نیست، علاقه به این حوزه در سالهای اخیر بهشدت افزایش یافته است. این طغیان بهدنبال مجموعهای از پیشرفتها رخ داد: یادگیری عمیق رکوردهای جدیدی در زمینههایی مثل تشخیص گفتار و زبان و همچنین بینایی ماشین به ثبت رساند. این موفقیتها به دو عامل وابسته بودند: یکی تعداد زیاد تصاویر، گفتار، ویدئو و متنی که برای آموزش سیستمهای یادگیری ماشین در دسترس بود.
اما مهمتر از هر چیز میتوان به ظهور مقادیر زیادی توان پردازش موازی بهویژه در زمینهی واحدهای پردازش گرافیکی مدرن (GPU-ها) اشاره کرد که میتوان برای نیروگاههای یادگیری ماشین از آنها استفاده کرد.
امروزه هر شخصی با اتصال اینترنتی میتواند از سرویسهای کلاد مثل آمازون، گوگل و مایکروسافت برای آموزش مدلهای یادگیری ماشین استفاده کند. با افزایش کاربرد یادگیری ماشین، شرکتها بهدنبال ساخت سختافزاری ویژه برای اجرا و آموزش مدلهای یادگیری ماشین هستند. نمونهای از این تراشههای سفارشی، واحد پردازش تانسوری گوگل (TPU) است که سرعت یادگیری ماشین را بالا میبرد و در چنین سرعتی مدلهای یادگیری ماشین با استفاده از کتابخانههای TensorFlow گوگل ساخته میشوند و میتوانند اطلاعات را از دادهها تفکیک کنند.
تراشههای یادشده نهتنها برای آموزش مدلهایی مثل Google DeepMind و Google Brain به کار میروند بلکه برای امکاناتی مثل گوگل ترنسلیت و تشخیص تصویر در Google Photo و همچنین سرویسهایی به کار میروند که امکان ساخت مدلهای یادگیری ماشین را با استفاده از قابلیت TensorFlow Research Cloud فراهم میکنند. نسل سوم این تراشهها در می ۲۰۱۸ در کنفرانس Google I/O رونمایی شدند.
در سال ۲۰۲۰، گوگل از چهارمین نسل TPU-ها با سرعت ۲.۷ برابر نسبت به TPU-های نسل قبلی در MLPerf خبر داد. بر اساس این شاخص سیستم با سرعتی بالا از طریق مدل آموزشدیدهی یادگیری ماشین قادر به استنتاج است. پیشرفتهای پیوستهی TPU امکان بهبود سرویسهای مربوط به مدلهای ممتاز یادگیری ماشین را به گوگل میدهند برای مثال میتوان مدلها را برای گوگل ترنسلیت آموزش داد.
با پیشرفت فزایندهی سختافزارها و اصلاح فریمورکهای نرمافزاری یادگیری ماشین، اجرای وظایف یادگیری ماشین برای تلفنهای هوشمند و کامپیوترها و استفاده از آنها بهجای دیتاسنترهای ابری متداول خواهد شد. گوگل در تابستان ۲۰۱۸، با پیشنهاد ترجمهی خودکار آفلاین برای ۵۹ زبان در اپلیکیشن Google Translate اندروید و iOS گام را فراتر گذاشت.
آلفاگو
شاید مشهورترین نماد بازدهی سیستمهای یادگیری ماشین را بتوان پیروی هوش مصنوعی آلفاگو از دیپمایند گوگل بر استاد بزرگ Go به شمار آورد که به نظر میرسد تا سال ۲۰۲۶ قابل پیشبینی نباشد. Go یک بازی سنتی چینی است که پیچیدگی بالای آن به مدت دهها سال کامپیوترها را گیج کرده بود. بازی گو دارای ۲۰۰ حرکت محتمل به ازای هر نوبت است درحالیکه تعداد حرکتها برای بازی شطرنج به بیست عدد میرسد. در طول بازی گو، حرکتهای محتمل زیادی وجود دارند که جستجوی هر کدام برای شناسایی بهترین اجرای بازی از دیدگاه محاسباتی بسیار پرهزینه است.
اما آلفاگو بر اساس حرکات بازیکنان خبرهی انسانی در بیش از ۳۰ میلیون بازی گو آموزش دیده بود و این دادهها وارد شبکههای عصبی یادگیری عمیق این بازی شدند. آموزش شبکههای یادگیری عمیق به زمان زیاد و مجموعهی عظیم دادهها نیاز دارد که بهتدریج برای اصلاح مدل و دستیابی به بهترین خروجی باید به سیستم تزریق شوند.
بااینحال، اخیرا گوگل فرایند آموزش را در نسخهی AlphaGo Zero بهبود داد. این سیستم قادر است بازیهای کاملا تصادفی را برای خود اجرا کند و از نتایج آنها بیاموزد. دمیس هاسابیس، مدیرعامل دیپمایند گوگل در کنفرانس سیستمهای پردازش اطلاعات عصبی (NIPS) در سال ۲۰۱۷ از آلفازیرو رونمایی کرد که نسخهی تعمیمیافتهای از آلفاگو زیرو است و در بازیهای شطرنج و شوگی به مهارت رسیده است.
پیشرفتهای دیپمایند در حوزهی یادگیری ماشین ادامه دارند. این شرکت در جولای ۲۰۱۸ از عوامل هوش مصنوعی رونمایی کرد که روش بازی شخص اول سهبعدی Quake III Arena را به خود آموزش دادهاند و بهراحتی میتوانند بازیکنان انسانی را شکست بدهند. این عوامل از همان اطلاعاتی استفاده کردند که بازیکنان انسانی استفاده میکنند با این تفاوت که از بازخورد عملکرد خود در طول بازی استفاده میکنند.
تأثیرگذارترین کاربرد پژوهشهای دیپمایند در اواخر ۲۰۲۰ با رونمایی از AlphaFold 2 نمود پیدا کرد. قابلیتهای این سیستم شاخص پیشرفتی برای علم پزشکی است. آلفافولد ۲ شبکهی عصبی متمرکز بر توجهی است که دارای پتانسیل افزایش سرعت مدلسازی بیماری و توسعهی دارو است. این سیستم میتواند ساختار سهبعدی پروتئینها را با تحلیل بلوکهای سازندهی آنها یعنی آمینواسیدها ترسیم کند. در ارزیابیهای رقابت پیشبینی ساختار پروتئینی، آلفافولد ۲ قادر به تعیین ساختار سهبعدی پروتئین با دقتی قابل قیاس با بلورنگاری است و میتواند در چند ساعت ساختارهای دقیق پروتئینی را مدلسازی کند.

آیا سیستمهای یادگیری ماشین هدفمند هستند
انتخاب و وسعت دادههای بهکاررفته برای آموزش سیستمها بر وظایف متناسب با آنها تأثیر میگذارد. همچنین نگرانیهای زیادی دربارهی چگونگی رمزنگاری انحرافها و نابرابریهای اجتماعی در سیستمهای یادگیری ماشین وجود دارد. برای مثال راشل تاتمن، پژوهشگر بنیاد علوم طبیعی و بخش زبانشناسی دانشگاه واشنگتن به این نتیجه رسید که سیستم تشخیص گفتار گوگل برای کپشنگذاری خودکار ویدئوهای یوتیوب برای صداهای مردانه عملکرد بهتری نسبت به صداهای زنانه دارد، در نتیجه به مجموعههای آموزشی نابرابر با برتری سخنگویان مرد اشاره کرد.
طبق یافتهها سیستمهای تشخیص چهره هم در شناسایی زنان و افراد رنگینپوست به مشکلاتی برخوردند. وجود خطاهای نژادی در چنین سیستمهایی باعث شد شرکتهای تولیدکننده، فروش برخی سیستمهای تشخیص چهره به پلیس را متوقف کنند. آمازون در سال ۲۰۱۸، ابزار یادگیری ماشین استخدامی را منسوخ کرد که بخش زیادی از درخواستکنندگان مرد را مطلوب ارزیابی کرده بود.
با حرکت سیستمهای یادگیری ماشین به سمت حوزههایی جدیدی مثل کمک به تشخیص پزشکی، احتمال انحراف سیستمها نسبت به پیشنهاد خدمات بهتر یا درمان عادلانه به گروه مشخصی از افراد به نگرانی عمدهای تبدیل شده است. پژوهشهای کنونی به سمت خنثیسازی انحراف در سیستمهای خودیادگیری پیش میروند.
آثار محیطی یادگیری ماشین
آثار محیطی تقویت و سردسازی مزارع محاسباتی که برای آموزش و راهاندازی مدلهای یادگیری ماشین به کار میروند سوژهی مقالهی انجمن اقتصاد جهانی در سال ۲۰۱۸ بودند. بر اساس یکی از تخمینهای سال ۲۰۱۹، نیروی مورد نیاز سیستمهای یادگیری ماشین هر ۳/۴ ماه دو برابر میشود.
از طرفی اندازهی مدلها و دیتاستهای بهکاررفته برای آموزش روزبهروز افزایش مییابند، برای مثال مدل پیشبینی زبانی GPT-3 نوعی شبکهی عصبی توزیعی با ۱۷۵ میلیارد پارامتر است. در نتیجه نگرانیها نسبت به آثار کربنی یادگیری ماشین افزایش مییابند.
انرژی مورد نیاز مدلهای یادگیری هم روزبهروز افزایش مییابند اما هزینهی راهاندازی مدلهای آموزشدیده با افزایش تقاضای خدمات مبتنی بر یادگیری ماشین روبه افزایش است. از طرفی تواناییهای قابل پیشبینی یادگیری ماشین تأثیر معنادار و مثبتی بر بسیاری از حوزههای کلیدی از محیط زیست تا بهداشت و درمان دارند.
دورههای آموزشی یادگیری ماشین
یکی از دورههای توصیهشده برای افراد تازهکار در حوزهی یادگیری ماشین، مجموعههای رایگان دانشگاه استنفورد است که توسط آندرو انجی کارشناس هوش مصنوعی و بنیانگذار Google Brain ارائه شدهاند. انجی اخیرا دورهی تخصص یادگیری عمیقی را منتشر کرده است که متمرکز بر مجموعهی گستردهای از عناوین و مباحث یادگیری ماشین و همچنین معماریهای شبکهی عصبی است. اگر بهدنبال یادگیری با روش بالا به پائین هستید، میتوانید کار را با اجرای مدلهای آموزشی یادگیری ماشین و سپس پرداختن به مباحث جزئی شروع کنید. دورهی یادگیری عمیق کاربردی برای کدنویسها از fast.ai هم برای توسعهدهندگانی که در زمینهی کار با پایتون تجربه دارند توصیه میشود.
هر دو دورهی فوق دارای نقاط قوتی هستند: دورهی انجی با ارائهی مروری بر مباحث تئوری یادگیری ماشین شروع میشود درحالیکه پیشنهاد fast.ai حول محور پایتون است. زمانیکه در میان مهندسان و دانشمندان دادهای یادگیری ماشین از کاربرد وسیعی برخوردار است. دورهی رایگان دیگر با کیفیت بالای آموزش و پوشش وسیع مباحث، مقدمهای بر یادگیری ماشین از دانشگاه کلمبیا و Edx است. البته برای این دوره نیاز به دانش اولیهای از ریاضیات سطح دانشگاه است.
سرویسهای موجود برای یادگیری ماشین
تمام پلتفرمهای اصلی ابری از جمله آمازون وبسرویس، مایکروسافت آژور و گوگل کلاد، امکان دسترسی به سختافزار مورد نیاز برای آموزش و راهاندازی مدلهای یادگیری ماشین را میدهند. کاربرها در پلتفرم کلاد گوگل میتوانند به تست TPU-ها بپردازند. TPU تراشههای سفارشی است که به منظور آموزش و راهاندازی مدلهای یادگیری ماشین بهینهسازی شده.
زیرساختهای ابری شامل مراکز دادهای موردنیاز برای حفظ مقادیر انبوه دادههای آموزشی، سرویسهای آمادهسازی تحلیل دادهای و ابزار بصریسازی برای نمایش واضح نتایج هستند. سرویسهای جدید همچنین امکان ساخت مدلهای سفارشی یادگیری ماشین را میدهند. برای مثال گوگل سرویسی به نام Cloud AutoML را برای خودکارسازی ساخت مدلهای هوشمند ارائه میکند. این سرویس درگ اند دراپ امکان ساخت مدلهای سفارشی تشخیص تصویر را فراهم میکند و کاربر برای کار با آن نیازی به هیچ تخصصی در زمینهی یادگیری ماشین ندارد. بهطور مشابهی آمازون هم از سرویسهای AWS خود برخوردار است که برای افزایش سرعت فرایند آموزش مدلهای یادگیری ماشین طراحی شدهاند.
پلتفرم هوش مصنوعی کلاد گوگل برای دانشمندان دادهای به مدیریت سرویس یادگیری ماشین پرداخته است و امکان آموزش، توسعه و خروجی گرفتن از مدلهای سفارشی یادگیری ماشین را بر اساس TensorFlow فریمورک یادگیری ماشین متنباز گوگل یا Keras، فریمورک شبکهی عصبی باز فراهم میکند.
ادمینهای پایگاه داده بدون سابقه در زمینهی علوم دادهای میتوانند از سرویس بتای گوگل به نام BigQueryML استفاده کنند که به ادمینها امکان برقراری تماس با مدلهای یادگیری ماشین آموزشدیده را با دستورهای SQL و امکان پیشبینی در پایگاه داده را میدهد؛ این فرایند سادهتر از خروجی گرفتن از دادهها برای تفکیک یادگیری ماشین و محیط تحلیلی است. برای سازمانهایی که بهدنبال ساخت مدلهای یادگیری ماشین خود نیستند، پلتفرمهای کلاد سرویسهای مبتنی بر تقاضای هوش مصنوعی مثل تشخیص صوتی، بصری و زبان را ارائه میکنند.
در عین حال IBM در کنار پیشنهادهای مبتنی بر تقاضا و عمومیتر، در تلاش است سرویسهای هوش مصنوعی تخصصی مثل بهداشت و درمان تا خردهفروشی را به فروش برساند. این پیشنهادها در گروه IBM Watson مدیریت میشوند.
گوگل در اوایل سال ۲۰۱۸ به توسعهی سرویسهای مبتنی بر یادگیری ماشین در دنیای تبلیغات پرداخت و مجموعهای از ابزار موردنیاز تبلیغات بهینهی فیزیکی و دیجیتالی را ارائه داد. از طرفی بااینکه اپل بهاندازهی گوگل و آمازون در زمینههای پردازش زبان طبیعی، تشخیص گفتار و بینایی ماشین از اعتبار برخوردار نیست، در حال سرمایهگذاری برای بهبود سرویسهای هوش مصنوعی خود است. رئیس سابق یادگیری ماشین گوگل در حال حاضر مسئول بخش استراتژی هوش مصنوعی اپل است که به توسعهی دستیار سیری و سرویس یادگیری ماشین Core ML اختصاص دارد.
انویدیا در سپتامبر ۲۰۱۸، به راهاندازی پلتفرم ترکیبی نرمافزاری و سختافزاری پرداخت که روی دیتاسنترها نصب میشود. این پلتفرم میتواند سرعت آموزش مدلهای یادگیری ماشین برای تشخیص صوت، ویدئو و تصویر و همچنین دیگر سرویسهای مرتبط با یادگیری ماشین را افزایش دهد.
کتابخانههای نرمافزاری
مجموعهی گستردهای از فریمورکهای نرمافزاری برای شروع کار آموزش و راهاندازی مدلهای یادگیری ماشین بهویژه برای زبانهای برنامهنویسی پایتون، R، C++، جاوا و متلب وجود دارند. پایتون و R پرکاربردترین و پرطرفدارترین زبانها در حوزهی یادگیری ماشین هستند.
نمونههای مشهور فریمورکها و کتابخانههای یادگیری ماشین عبارتاند از: TensorFlow گوگل، کتابخانهی متنباز Keras، کتابخانهی scikit learn پایتون، فریمورک یادگیری عمیق CAFFE و کتابخانهی یادگیری ماشین Torch.
کاربردهای یادگیری ماشین در زندگی روزمره
علاقه به یادگیری ماشین در حوزههای مختلف رو به افزایش است چرا که حجم دادههای در دسترس به مرور زمان افزایش مییابد. یادگیری ماشین از تکنیکهای فراوانی برای استخراج اطلاعات از دادهها برخوردار است و میتواند بهصورت هدفمند از این اطلاعات استفاده کند.
الگوریتمهای یادگیری ماشین میتوانند اطلاعات میدانی و توابع خودکار مربوط به تنظیم و بهینهسازی را تقویت کنند. علاوه بر این یادگیری ماشین همراهبا یادگیری ماشین میتواند در بسیاری از حوزهها مثل تشخیص پزشکی، تحلیل دادههای آماری و الگوریتمها، پژوهشهای علمی و بسیاری از حوزههای دیگر مفید واقع شود. امروزه یادگیری ماشین را میتوان در اپلیکیشنهای تلفن هوشمند، دستگاههای کامپیوتری، وبسایتهای آنلاین، امنیت سایبری و بسیاری از موارد دیگر پیدا کرد. در ادامه به رایجترین کاربردهای یادگیری ماشین در زندگی روزمره اشاره شده است.

کاربردهای یادگیری ماشین در زندگی روزمره
تخمین جابهجایی
بهطور کلی، زمان یک سفر ممکن است بیش از زمان میانگین باشد؛ چرا که حالتهای متعدد حملونقل از جمله زمانبندی ترافیک بر زمان رسیدن به مقصد تأثیر میگذارند. کاهش زمان سفر کار سادهای نیست اما در ادامه میبینیم که یادگیری ماشین چگونه به این مشکل کمک میکند:
- گوگل مپز: گوگل مپز با استفاده از دادههای موقعیت تلفنهای هوشمند به بررسی میزان سرعت انتقال ترافیک در هر زمان میپردازد علاوه بر این نقشه میتواند ترافیک گزارششده توسط کاربر از جمله احتمال ساخت و ساز، ترافیک خودرو و تصادفها را سازماندهی کند. گوگل مپز با دسترسی به دادههای مرتبط و الگوریتمهای مناسب، میتواند زمان سفر را با نمایش سریعترین مسیر کاهش دهد.
- اپلیکیشنهای سواری: مواردی مثل پرداخت هزینهی سواری و کاهش زمان انتظار از جمله مشکلات حملونقل شهری هستند؛ اما یادگیری ماشین به حل این مشکل کمک میکند و به شرکتها در تخمین هزینهی جابهجایی، محاسبهی موقعیت بهینهی سوار شدن و تضمین کوتاهترین مسیر و کشف فریب کمک میکند. برای مثال اوبر از یادگیری ماشین برای بهینهسازی خدمات خود استفاده میکند.
- پروازهای تجاری و استفاده از اتوپایلوت: به کمک فناوری هوش مصنوعی، اتوپایلوتها به کنترل پروازهای کنونی میپردازند. بر اساس گزارش نیویورک تایمز، خلبانها تنها هفت دقیقه در طول تیکاف و فرود، پرواز را بهصورت دستی کنترل میکند و سایر پرواز بهصورت اوتوپایلت یا خودکار ادامه مییابد.
هوش ایمیل
- فیلترهای اسپم: برخی فیلترهای قانون محور نقش فعالی در اینباکس ندارند. برای مثال وقتی پیامی با کلمات «مشاورهی آنلاین»، «داروخانهی آنلاین» یا «آدرس ناشناس» دریافت میشوند. یادگیری ماشین قابلیت قدرتمندی را برای فیلتر انواع نشانههای ایمیلی از جمله کلمات موجود در پیغام، متادادهی پیام ارائه میکند. جیمیل با استفاده از یادگیری ماشین، ۹۹.۹ درصد از پیامهای اسپم را فیلتر میکند.
- طبقهبندی ایمیل: جیمیل، ایمیلها را به گروههای Primary، Promotions، Social و Update دستهبندی میکند و ایمیلها را بر اساس درجهی اهمیت دستهبندی میکند.
- پاسخهای هوشمند: جیمیل میتواند عبارتهای سادهای را مثل «متشکرم» در پاسخ به خواننده ارسال کند. این پاسخها بر اساس هر ایمیل سفارشی میشوند.
بانکداری و امور مالی
- پیشگیری از فریب: در اغلب نمونهها، حجم دادههای تراکنش روزمره بسیار بالا است و بررسی دستی هر تراکنش فرآیندی پیچیده است. برای حل این مشکل، سیستمهای مبتنی بر هوش مصنوعی طراحی شدهاند که تراکنشهای گمراهکننده را کشف میکنند. بانکها از این قابلیت هوش مصنوعی استفاده میکنند. شرکتها هم از شبکههای عصبی برای شناسایی تراکنشهای جعلی بر اساس معیارهایی مثل آخرین تکرار تراکنش، اندازهی تراکنش و نوع خردهفروش استفاده میکنند.
- تصمیمهای اعتباری: مؤسسههای مالی از الگوریتمهای یادگیری ماشین برای اتخاذ تصمیمهای اعتباری و ارزیابی ریسک هر کاربر استفاده میکنند.
- بررسی چک در موبایل: علاوه بر این فناوری هوش مصنوعی بانکداری را برای افرادی که وقتی برای مراجعه به بانک ندارند، آسان و سفارشی ساخته است. برای مثال بانکها امکان تأیید چک را از طریق اپلیکیشن تلفن هوشمند فراهم میکنند و دیگر نیازی نیست کاربر بهصورت فیزیکی چک را به بانک تحویل دهد. اغلب بانکها از فناوری Mitek برای تفسیر و تبدیل دستنوشتهی چکها به متن از طریق تشخیص کاراکتر استفاده میکنند.
ارزیابی
- بررسی سرقت ادبی: از یادگیری ماشین میتوان برای ساخت آشکارساز سرقت ادبی استفاده کرد. بسیاری از مدارس و دانشگاهها به ارزیاب سرقت ادبی و تحلیل مهارت نوشتاری دانشجویان و دانشآموزان نیاز دارند. در الگوریتم سرقت ادبی از توابع تشابه استفاده میشود که برابری دو سند را بررسی میکنند.
- قرائتگرهای خودکار: در گذشته رتبهبندی رساله وظیفهای بسیار پیچیده بود اما در حال حاضر پژوهشگرها و سازمانها بهدنبال ساخت سیستمهای هوش مصنوعی برای نمره دهی و رتبهبندی رساله هستند. آزمون GRE مقالهها را از طریق یک قرائتگر انسانی و یک قرائتگر خودکار به نام e-Rater رتبهبندی میکند. اگر نمرهها دارای تفاوت قابل توجهی باشند، یک قرائتگر انسانی دوم برای تخمین این تفاوت در نظر گرفته میشود.
در آیندهای نزدیک، کلاسهای کنونی با یادگیری انعطافپذیر و سفارشی جایگزین میشوند که نقاط قوت و نقاط ضعف هر دانشآموز را در نظر میگیرند. یادگیری ماشین همچنین به شناسایی دانشآموزان در معرض خطر کمک میکند در نتیجه مدارس میتوانند با ارائهی دورههای فوق برنامهی یادگیری، بیشتر به این دانشآموزان توجه کنند. برای مثال هوش مصنوعی در بخش آموزش به یادگیری سفارشی، دستیارهای صوتی و انجام وظایف مدیریتی کمک میکند.
شبکههای اجتماعی
- فیسبوک: هنگام بارگذاری تصویر در فیسبوک، چهرهها بهصورت خودکار تشخیص داده میشوند و تگ دوستان پیشنهاد میشود. فیسبوک از هوش مصنوعی و یادگیری ماشین برای شناسایی چهرهها استفاده میکند. دیگر موارد کاربرد هوش مصنوعی در فیسبوک عبارتاند از:
- از الگوریتم ANN استفاده میکند که از مغز انسان تقلید میکند و نرمافزار تشخیص چهره را تقویت میکند.
- کاربران فیسبوک از هوش مصنوعی برای سفارشیسازی خبرنامه و اطمینان از انعکاس پستها استفاده میکنند.
- تبلیغات مرتبط با علاقه و کسبوکارهای مشخص را نمایش میدهد.
- پینترست: پینترست از بینایی ماشین برای خودکارسازی تشخیص اشیاء در تصاویر یا به اصلاح «پین» کردن آنها استفاده میکند و سپس پینهای مشابه را توصیه میکند. همچنین از قابلیتهای دیگر هوش مصنوعی و یادگیری ماشین برای جستوجو، کشف، بازاریابی ایمیلی و بهبود عملکرد تبلیغات استفاده میکند.
- اسنپچت: فیلترهای چهره را پیشنهاد میدهد (موسوم به لنز) که فعالیت چهره را فیلتر و پیمایش میکنند، به کاربران اجازه میدهند تصاویر متحرک یا ماسکهای دیجیتال را تگ کنند که هنگام حرکت صورت جابهجا میشوند.
- اینستاگرام: به کمک الگوریتمهای یادگیری ماشین، هدف ایموجیها قابل شناسایی است. اینستاگرام ایموجیهای خودکار و هشتگهای ایموجی را پیشنهاد میدهد. همچنین از طریق ترجمهی ایموجی به متن میتوان در سطح گستردهای به کشف ایموجیها پرداخت.
بهداشت و درمان و تشخیص پزشکی
یادگیری ماشین از مجموعهای از ابزار و روشها برای تشخیص و پیشبینی مشکلات در حوزههای مختلف پزشکی استفاده میکند. الگوریتمهای یادگیری ماشین در علم پزشکی برای موارد ذیل به کار میروند:
- تحلیل دادههای پزشکی برای کشف الگو در دادهها
- کنترل دادههای نامناسب
- توصیف دادههای تولیدشده توسط واحدهای پزشکی
- نظارت بهینه بر بیماران
یادگیری ماشین به تخمین پیشرفت بیماری، کنترل اطلاعات پزشکی برای پژوهش خروجیها، برنامهریزی و کمک به درمان و مدیریت کلی بیمار کمک میکند. هوش مصنوعی علاوه بر یادگیری ماشین برای نظارت مؤثر هم به کار میرود.
دستیار شخصی هوشمند
از سیری تا کورتانا تا گوگل اسیستنت، الکسای آمازون و گوگلهوم، دستیارهای شخصی مزایا و قابلیتهای زیادی دارند. با پیادهسازی هوش مصنوعی این دستیارها تابع دستوراتی مثل تنظیم یادآور، جستجوی اطلاعات آنلاین، کنترل نورها و بسیاری از موارد دیگر هستند.
دستیارهای فردی از جمله رباتهای چت یادگیری ماشین مبتنی بر الگوریتمهای یادگیری ماشین هستند که به جمعآوری اطلاعات میپردازند، اولویتها را درک میکنند و تجربهی کاربری را بر اساس تعامل با افراد بهبود میدهند.
سخن پایانی
یادگیری ماشین با پردازش و تحلیل دادههای انبوه بسیاری از وظایف انسان را ساده ساخته است. این فناوری در حال حاضر در بسیاری از برنامهها و دستگاههای زندگی روزمره از جمله تلفنهای هوشمند، لوازم خانگی و شبکههای اجتماعی به کار میرود. در حوزهی علم، یادگیری ماشین بسیاری از وظایف سنگین و طاقتفرسا را برای پژوهشگران آسان ساخته است. با توجه به روند رو به رشد این فناوری در آینده شاهد کاربردهای گستردهتر یادگیری ماشین در تمام حوزههای زندگی انسان خواهیم بود.
