هرآنچه از معماری Ada Lovelace انویدیا و گرافیکهای RTX 4000 میدانیم

درحالحاضر شایعات زیادی درباره برنامههای انویدیا برای معماری Ada Lovelace وجود دارد؛ کارتهای گرافیک RTX 4000 انویدیا با معماری Ada Lovelace قرار است تا پایان سال ۲۰۲۲، یعنی دو سال پس از معماری Ampere تیم سبز و احتمالاً زمانی بین سپتامبر و اکتبر (شهریور و مهر ۱۴۰۱) به بازار عرضه شوند. انویدیا معماری این گرافیکها را بهافتخار ریاضیدان مشهور و اولین برنامهنویس تاریخ، آدا لاولیس مینامد.
در اوایل اسفند ۱۴۰۰، گروهی از هکرها به سرورهای انویدیا حمله کردند و درنتیجه حجم قابلتوجهی اطلاعات دربارهی پردازندههای گرافیکی این شرکت به بیرون درز پیدا کرد. در ادامه با زومیت همراه باشید تا هرآنچه تا به این لحظه درمورد معماری Ada Lovelace انویدیا و خانواده سری RTX 40 میدانیم باهم مرور کنیم.
عناوینی که در این مقاله خواهید خواند:
- افزایش چشمگیر عملکرد محاسباتی در معماری Ada
- حدس و گمان دربارهی واحد خروجی رندر در معماری Ada
- شایعات تردیدبرانگیز دربارهی تعداد واحدهای محاسباتی
- سابسیستم حافظه: احتمال استفاده از GDDR6X
- استفاده از حافظهی کش L2 قابلتوجه
- مصرف برق در معماری Ada
- نامگذاری کارت گرافیکهای مبتنی بر معماری Ada
- قیمتگذاری کارتهای گرافیک مبتنی بر معماری Ada
- تغییرات در طراحی Founders Edition کارتهای گرافیک Ada
- زمان عرضهی پردازندههای گرافیکی Ada
- رقابت بیشتر در فضای پردازندههای گرافیکی
تیم سبز اوایل فروردین پردازندههای گرافیکی مرکز دادهی هاپر H100 خود را به تفصیل معرفی کرد، معماری هاپر و پردازندهی گرافیکی H100 را نباید با معماری Ada اشتباه گرفت. درواقع هاپر H100 جایگزینی برای Ampere A100 خواهد بود که خود جایگزین Volta V100 است. با بررسی روال عرضهی محصولات انویدیا، انتظار میرود که محصولات مصرفی دیگر این شرکت مانند کارتهای گرافیک نیز در آیندهای نه چندان دور عرضه شوند.
برای مثال، پردازندهی گرافیکی A100 بهطور رسمی در مه ۲۰۲۰ معرفی شد و پردازندههای گرافیکی مصرفی Ampere در قالب کارتهای گرافیک RTX 3080 و RTX 3090 حدود چهار ماه بعد از آن عرضه شدند. در صورتی که انویدیا برنامهی مشابهی برای عرضهی پردازندههای گرافیکی مبتنی بر معماری Ada Lovelace را دنبال کند، میتوان احتمال داد که کارتهای گرافیک RTX 40 نیز با همین فاصله زمانی و بین ماههای اوت تا سپتامبر عرضه شوند.
| پردازندهی گرافیکی | AD102 | AD103 | AD104 | AD106 | AD107 |
|---|---|---|---|---|---|
| فرایند ساخت | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N |
| تعداد ترانزیستورها | احتمالاً ۶۰ میلیارد | احتمالاً ۴۰ میلیارد | احتمالاً ۳۰ میلیارد | احتمالاً ۲۰ میلیارد | احتماالا ۱۵ میلیارد |
| واحدهای محاسباتی | ۱۴۴ | ۸۴ | ۶۰ | ۳۶ | ۲۴ |
| تعداد هستههای CUDA | ۱۸٬۴۳۲ | ۱۰٬۷۵۲ | ۷٬۶۸۰ | ۴٬۶۰۸ | ۳٬۰۷۲ |
| تعداد هستههای تنسور | ۵۷۶ | ۳۳۶ | ۲۴۰ | ۱۴۴ | ۹۶ |
| تعداد هستههای RT | ۱۴۴ | ۸۴ | ۶۰ | ۳۶ | ۲۴ |
| فرکانس توربو | ۱٫۶ تا ۲٫۰ گیگاهرتز | ۱٫۶ تا ۲٫۰ گیگاهرتز | ۱٫۶ تا ۲٫۰ گیگاهرتز | ۱٫۶ تا ۲٫۰ گیگاهرتز | ۱٫۶ تا ۲٫۰ گیگاهرتز |
| حافظهی کش L2 (مگابایت) | ۹۶ | ۶۴ | ۴۸ | ۳۲ | ۳۲ |
| سرعت VRAM (گیگابیتبرثانیه) | ۲۱ تا ۲۴ | ۲۱ تا ۲۴ | ۱۶ تا ۲۱ | ۱۶ تا ۲۱ | ۱۴ تا ۲۱ |
| پهنای باس حافظهی ویدئویی (بیت) | ۳۸۴ | ۲۵۶ | ۱۹۲ | ۱۲۸ | ۱۲۸ |
| واحد خروجی رندر (ROP) | احتمالاً بین ۱۲۸ تا ۱۹۶ | احتمالاً ۱۱۲ | احتمالاً ۹۶ | احتمالاً ۶۴ | احتمالاً ۴۸ |
| واحد مپینگ بافت (TMU) | ۵۷۶ | ۳۳۶ | ۲۴۰ | ۱۴۴ | ۹۶ |
| قدرت انجام محاسبات ممیز شناور تکدقتی (FP32) | ۵۹ تا ۷۳٫۷ ترافلاپس | ۳۴٫۴ تا ۴۳ ترافلاپس | ۲۴٫۶ تا ۳۰٫۷ ترافلاپس | ۱۴٫۷ تا ۱۸٫۴ ترافلاپس | ۹٫۸ تا ۱۲٫۳ ترافلاپس |
| قدرت انجام محاسبات ۱۶ بیت نیمدقتی (FP16) | ۴۷۲ تا ۵۹۰ ترافلاپس | ۲۷۵ تا ۳۴۴ ترافلاپس | ۱۹۷ تا ۲۴۶ ترافلاپس | ۱۱۸ تا ۱۴۷ ترافلاپس | ۷۹ تا ۹۸ ترافلاپس |
| پهنای باند (گیگابایتبر ثانیه) | ۱۰۰۸ تا ۱۱۵۲ | ۶۷۲ تا ۷۶۸ | ۳۸۴ تا ۵۰۴ | ۲۵۶ تا ۳۳۶ | ۲۲۴ تا ۳۳۶ |
| توان طراحی حرارتی | کمتر از ۶۰۰ وات | کمتر از ۴۵۰ وات | کمتر از ۳۰۰ وات | کمتر از ۲۲۵ وات | کمتر از ۱۵۰ وات |
| قیمت حدودی | بیشتر از هزار دلار | بین ۶۰۰ تا هزار دلار | بین ۴۵۰ تا ۶۰۰ دلار | بین ۳۰۰ تا ۴۵۰ دلار | بین ۲۰۰ تا ۳۰۰ دلار |
مشخصات شایعهشدهی پردزاندههای گرافیکی Ada
تخمینهایی که در مقالهی پیشرو برای فرکانس پردازندههای گرافیکی Ada در نظر گرفتهشده، مطابق با معماریهای قبلی Turing و Ampere و عددی بین ۱٫۶ تا ۲٫۰ گیگاهرتز است و با اینکه احتمال دارد انویدیا فرکانسهایی فراتر از این مقدار را برای این نسل از پردازندههای گرافیکی فراهم کند، ما فعلاً به تخمینی محافظهکارانه بسنده میکنیم.
یکی دیگر از پیشفرضهای در نظر گرفتهشده در مقالهی پیشرو، استفاده از فرایند سفارشی TSMC 4N (یا همان فرایند ۴ نانومتری) در همهی پردازندههای گرافیکی Ada است.
پردازندهی گرافیکی هاپر H100 با فرایند 4N TSMC تولید میشود؛ به نظر میرسد این فرایند نوعی فرایند تغییریافتهی N5 TSMC باشد که بهطور گسترده در تراشههای آیفونها و لپتاپهای اپل استفاده میشود و براساس برخی شایعات قرار است همین فرایند برای تولید پردازندههای گرافیکی مبتنی برای Ada انویدیا، پردازندههای مبتنی بر Zen 4 و پردازندههای گرافیکی مبتنی بر RDNA 3 نیز بهکار رود؛ باید توجه داشت که امروزه نام گرههای فرایند (عدد نانومتر) دیگر ربطی به ویژگیهای فیزیکی تراشهها ندارد و مقیاس فیزیکی تراشهها تنها بهعنوان نمادهایی برای بازاریابی به حساب میآیند.
میدانیم پردازندهی گرافیکی هاپر H100 حدودا ۸۰ میلیارد ترانزیستور خواهد داشت و پردازندهی گرافیکی A100، دو برابر GA102، یعنی ۵۶ میلیارد ترانزیستور دارد. حالا براساس برخی گزارشها به نظر میرسد که انویدیا قصد دارد در پردازندهی گرافیکی AD102، تعداد ترانزیستورها را حتی بیشتر از دوبرابر ترانزیستورهای H100 افزایش دهد.
بنابر اطلاعاتی که تا به این لحظه به بیرون درز پیدا کرده و حداقل روی کاغذ، به نظر میرسد معماری Ada، عملکردی بسیار چشمگیر داشته باشد. در معماری Ada تعداد واحدهای محاسباتی (SMs) یا Streaming Multiprocessors و هستههای مرتبط با آنها بسیار بیشتر از پردازندههای گرافیکی فعلی Ampere است و همین امر بهتنهایی میتواند عملکرد را بهصورت قابلتوجهی افزایش دهد.
واحدهای محاسباتی (SMs) یا Streaming Multiprocessors، بخشی در پردازندههای گرافیکی انویدیا هستند که برای محاسبهی عملیات به کار میروند.

با بررسی پردازندهی گرافیکی هاپر H100 ممکن است جزئیاتی دربارهی معماری Ada کشف شود
حتی اگر مشخصات معماری Ada از آنچه به بیرون درز پیدا کرده هم ضعیفتر باشد، بازهم میتوان اطمینان داشت که این معماری عملکرد بهتری برای پردازندههای گرافیکی نسل بعدی به همراه خواهد داشت و کارت گرافیک RTX 4090، پیشرفتی بزرگ نسبت به کارت گرافیک RTX 3090 Ti محسوب خواهد شد.
کارت گرافیک RTX 3080 در زمان عرضه حدود ۳۰ درصد و کارت گرافیک RTX 3090 نیز ۴۵ درصدسریعتر از کارت گرافیک RTX 2080 Ti بودند. بنابراین در نظر داشته باشید که اگر از پردازندهای معمولی مانند Core i9-12900K یا Ryzen 7 5800X3D استفاده میکنید برای استفادهی حداکثری از تمام توان و سرعت پردازندههای گرافیکی Ada نیاز خواهید داشت که پردتزندهی سیستم خود را ارتقا دهید.
افزایش چشمگیر عملکرد محاسباتی در معماری Ada
در ابتدا به معرفی انواع هستههای موجود در پردازندههای گرافیکی سری RTX انویدیا میپردازیم.
- اولین نوع، هستههای CUDA هستند که برای انجام محاسبات عمومی کاربرد دارند؛ هزاران تعداد از این هستهها بهطور موازی روی پردازندههای گرافیکی مدرن قرار میگیرند و نحوهی سایه انداختن هر پیکسل و تمام جلوههای دیگر گرافیکها را بر عهده دارند.
- در مرحله بعد، کارتهای RTX هستههایی به نام تنسور (Tensor) دارند که نوع دیگری از محاسبات، یعنی محاسبات یادگیری ماشینی و هوش مصنوعی را انجام میدهند. این هستهها را میتوان برای تسریع نرمافزار یادگیری ماشینی در هر حوزهای استفاده کرد، اما در گرافیک نیز نقش مهمی ایفا میکنند. انویدیا از هستههای تنسور برای بهبود تصاویر رهگیری پرتو و همچنین نمونهبرداری هوشمندانه از تصاویر ارائهشده با وضوح پایینتر با استفاده از فناوری DLSS (نمونهگیری فوقالعاده یادگیری عمیق) استفاده میکند.
- در نهایت، به هستههای RT میرسیم که وظیفه دارند محاسبات رهگیری پرتو را در سریعترین زمان ممکن انجام دهند تا تصویری متحرک روی صفحهای با نرخ فریم قابل پخش، نمایش داده شود. درواقع هستههای RT بهطور خاص ریاضیات کلیدی مورد نیاز برای رهگیری پرتوهای مجازی نور را در یک تصویر تسریع میکنند.
مهمترین تغییر در پردازندههای گرافیکی Ada، افزایش تعداد واحدهای محاسباتی (SMs) در هستههای CUDA در مقایسه با پردازندههای گرافیکی نسل فعلی Ampere خواهد بود. پردازندهی گرافیکی AD102 در بهترین شرایط ممکن ۷۱ درصد بیشتر از پردازندهی گرافیکی GA102 واحد محاسباتی (SMs) دارند و حتی اگر تمام پیشرفتهای دیگری این معماری را نیز نادیده بگیریم، بازهم تنها همین افزایش توان محاسباتی(SMs) میتواند بهبود چشمگیری در عملکرد پردازندههای گرافیکی نسل بعدی محسوب شود.
افزایش تعداد واحدهای محاسباتی نهتنها برای عملکرد گرافیکی بلکه برای در سایر زمینهها نیز کارآمد خواهد بود. برای مثال محاسبات معماری Ampere روی هستهی تنسور و یک تراشهی کاملاً فعال AD102 با فرکانسی نزدیک به ۲ گیگاهرتز، میتواند قدرت محاسبهی یادگیری عمیق یا محاسبات هوش مصنوعی را به ۵۹۰ ترافلاپس در محاسبات ۱۶ بیت نیمدقتی (FP16) برساند. (هستههای تنسور از نوآوریهای انویدیا در دنیای پردازش گرافیکی هستند که در یادگیری عمیق و شبکهی عصبی کاربرد بسیار زیادی دارند).

برای مقایسه، پردازندهی گرافیکی GA102 در کارت گرافیک RTX 3090 Ti در بهترین حالت به ۳۲۱ ترافلاپس در محاسبات نیمدقتی دست پیدا میکند؛ افزایش ۸۴ درصدی قدرت محاسباتی که براساس شمارش هسته و فرکانس محاسبه میشود، به احتمال زیاد در مورد سختافزار رهگیری پرتو نیز صدق میکند. همهی این درصدها در صورتی میتوانند درست باشند که انویدیا تغییری در هستههای RT و تنسور ایجاد نکند.
براساس برخی گزارشها به نظر میرسد تغییرات گستردهای در هستههای تنسور نیاز نباشد و بهبودهای سختافزار یادگیری عمیق، بیشتر برای پردازندهی گرافیکی هاپر H100 اعمال شود تا گرافیک AD102 مبتنی بر معماری Ada.
از سوی دیگر ممکن است در هستههای RT اصلاحاتی اعمال شود که عملکرد آنها را ۲۵ تا ۵۰ درصد نسبت به معماری Ampere افزایش دهد؛ درست مانند بهبود عملکرد ۷۵ درصدی هستههای RT معماری Ampere که نسبت به معماری Turing اعمال شده بود.
در بدترین سناریو تنها استفاده از لیتوگرافی 4N TSMC (یا حتی 5N TSMC) به جای لیتوگرافی 8N سامسونگ، افزودن هستههای بیشتر و حفظ فرکانسهای مشابه میتواند تا حد قابلقبولی عملکرد پردازندههای گرافیکی نسل بعدی را افزایش دهد؛ با اینکه احتمال دارد انویدیا به این تغییر حداقلی بسنده نکند، اما حتی با همین تغییرات نیز پردازندهی گرافیکی ردهپایین AD107 نسبت به RTX 3050 فعلی ۳۰ درصد یا بیشتر بهبود خواهد یافت.
به خاطر داشته باشید که تعداد واحدهای محاسباتی ذکرشده برای تراشهای کامل است و به احتمال زیاد انویدیا از تراشههایی نیمهفعال برای بهبود بازده استفاده خواهد کرد.
برای مثال پردازندهی گرافیکی هاپر H100 واحد محاسباتی برابر با ۱۴۴ دارد، اما تنها ۱۳۲ واحد از این تعداد در نسخهی SXM5 فعال است؛ احتمالاً همین رویکرد را در پردازندهی گرافیکی AD102 (کارت گرافیک RTX 4090) نیز شاهد خواهیم بود؛ به این معنی که تعداد واحدهای محاسباتی فعال برای AD102 بین ۱۳۲ تا ۱۴۰ و در نسخههای پایینردهتر نیز کمتر از این عدد خواهد بود. انویدیا با این کار میتواند امکان بازده بیشتر کارت گرافیک آینده (یعنی RTX 4090 Ti) را ازطریق فعال کردن کامل تمام واحدهای محاسباتی فراهم کند.
حدس و گمان دربارهی واحد خروجی رندر در معماری Ada
واحد خروجی رندر (Render OutPut unit) که اغلب به اختصار ROP خوانده میشود، جزئی سختافزاری در واحدهای پردازش گرافیکی و یکی از مراحل نهایی در فرایند رندر کارتهای گرافیک است. ROP-ها تراکنشهای بین بافرها یا همان نوشتن، خواندن و ترکیب آنها با یکدیگر را در حافظهی محلی انجام میدهند و با کمک سختافزارهایی که دارند، باعث میشوند تصاویر خروجی زیباتر و با حداقل واپیچیدگیهای مصنوعی نمایش داده شوند.
درحالحاضر اطلاعات زیادی در مورد واحدهای خروجی رندر (ROPs) پردازندههای گرافیکی Ada در دست نیست، اما میدانیم که در معماری Ampere، واحدهای خروجی رندر به خوشههای پردازش گرافیکی (GPCs) وابسته بودند؛ خوشهی پردازش گرافیکی (GPC) که بلوک سختافزاری اختصاصی برای محاسبات، سایهزنی و بافتدهی است؛ از ۴ خوشهی پردازش بافت (TPC) تشکیل شده است که هرکدام تعدادی نامعلوم واحد محاسباتی (SMs) و یک موتور شطرنجی (Raster Engine) دارند؛ حتی اگر تعداد واحدهای محاسباتی را بدانیم، بازهم مشخص نیست که هر خوشهی پردازش گرافیکی (GPC) چند SMs خواهد داشت.
برای مثال، اگر تعداد کل واحدهای محاسباتی AD102 را ۱۴۴ واحد در نظر بگیریم، ۱۲ خوشهی پردازش گرافیکی خواهیم داشت که هر کدام ۱۲ واحد محاسباتی دارند؛ اگر تعداد خوشههای پردازش گرافیکی را ۸ واحد فرض کنیم، ۱۸ واحد محاسباتی و اگر این تعداد را ۹ واحد فرض کنیم، ۱۶ واحد محاسباتی خواهیم داشت. البته ترکیبهای دیگری نیز برای تعداد خوشههای پردازش گرافیکی و واحدهای محاسباتی وجود دارد، اما این سه ترکیب از تمام حالتهای دیگر محتملتر به نظر میرسد.
ازآنجاکه پردازندهی گرافیکی هاپر H100 هشت خوشهی پردازش گرافیکی با ۱۸ واحد محاسباتی دارد؛ با نادیده گرفتن حافظهی HBM3، این پیکربندی شاید حتی پیکربندی معقولتری برای AD102 باشد.
شایعات تردیدبرانگیز دربارهی تعداد واحدهای محاسباتی معماری Ada
تعداد ۱۴۴ واحد محاسباتی (SMs) برای AD102 کمی مشکوک به نظر میرسد؛ پردازندهی گرافیکی GA100 حداکثر ۱۲۰ واحد محاسباتی داشت و تراشهی هاپر H100 حدود ۲۰ درصد بیشتر از این تعداد، یعنی ۱۴۴ واحد محاسباتی دارد که در بهترین حالت ۱۳۲ واحد از این تعداد فعال هستند. از طرف دیگر، برخی شایعات حاکی از آن است که تعداد واحدهای محاسباتی پردازندهی گرافیکی AD102 حدود ۷۱ درصد از GA102 بیشتر است؛ بنابراین بعید به نظر میرسد که تعداد واحدهای محاسباتی Ada و هاپر برابر باشد.
درواقع تنها استناد به دادههایی که از انویدیا به بیرون درز پیدا کرده است، نمیتواند درستی حدس و گمانهای بالا را تأیید کند. شاید بهتر بود که انویدیا نیز مانند ایامدی و معماری RDNA2 تیم قرمز، معماری جدید خود را با تنظیم فرکانسهای بالاتر و تعداد واحدهای محاسباتی کمتری ارائه میکرد، اما انجام چنین کاری به بازنگری اساسیتری در معماری نیاز داشت.
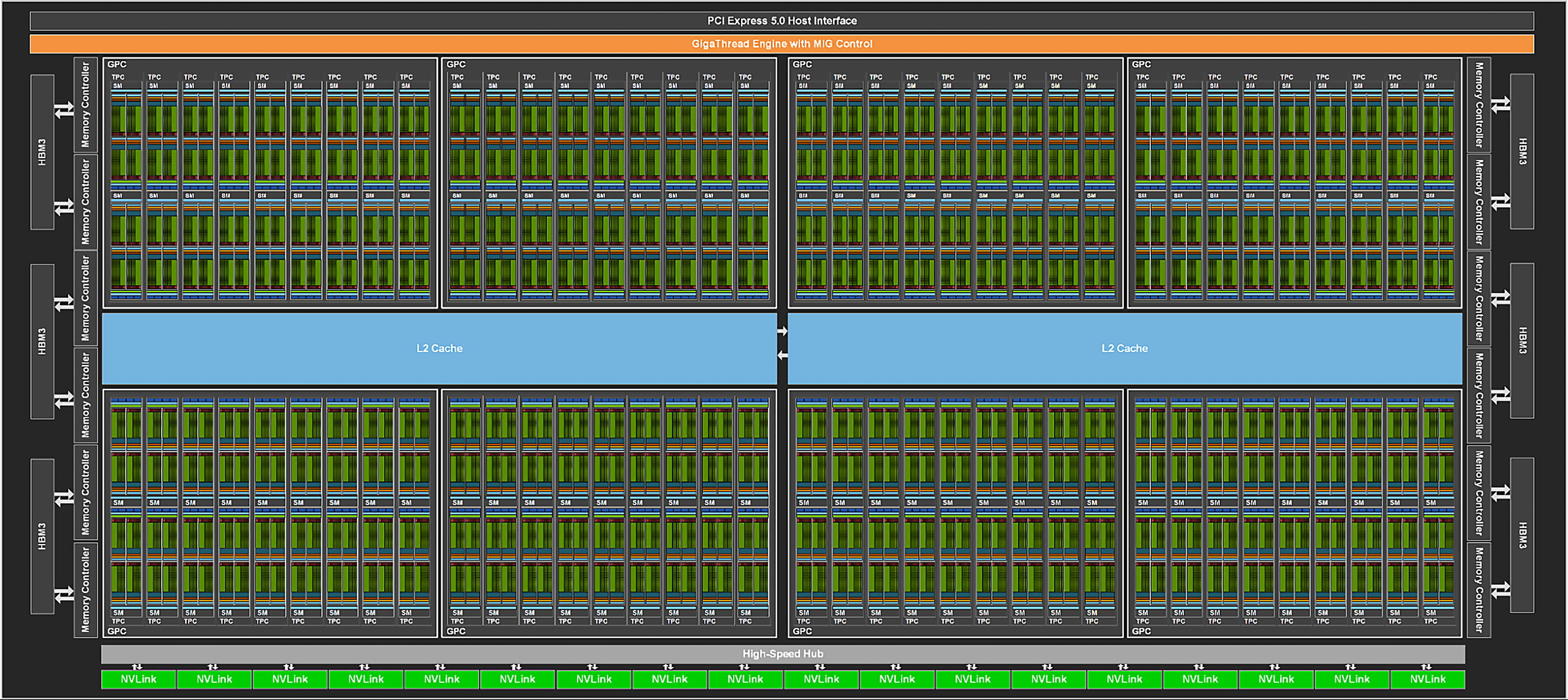 پردازندهی گرافیکی هاپر H100 به ۱۴۴ واحد محاسباتی مجهز است و ۸ خوشهی پردازش گرافیکی دارد. HBM3 را در این پردازندهی گرافیکی با GDDR6X جایگزین کنید، اکثر هستههای FP64 (با قدرت محاسبات اعشاری با دقت مضاعف) را نیز به هستههای تنسور تغییر دهید، سپس هستههای RT را اضافه کنید؛ حالا از نظر تئوری ممکن است به پردازندهی گرافیکی AD102 مبتنی بر معماری Ada برسید.
پردازندهی گرافیکی هاپر H100 به ۱۴۴ واحد محاسباتی مجهز است و ۸ خوشهی پردازش گرافیکی دارد. HBM3 را در این پردازندهی گرافیکی با GDDR6X جایگزین کنید، اکثر هستههای FP64 (با قدرت محاسبات اعشاری با دقت مضاعف) را نیز به هستههای تنسور تغییر دهید، سپس هستههای RT را اضافه کنید؛ حالا از نظر تئوری ممکن است به پردازندهی گرافیکی AD102 مبتنی بر معماری Ada برسید.
از سوی دیگر، برای بزرگ بودن تراشهی AD102 نیز دلیل قانعکنندهای وجود دارد: وجود سختافزار رهگیری پرتو.
همانطورکه میدانیم انویدیا سیلیکونی کاملاً مجزا برای دو قشر مصرفکننده و حرفهای نمیسازد. برای مثال تیم سبز در گرافیک 3090Ti از همان تراشهی GA102 موجود در گرافیک RTX 3080 و کمی قابلیت اضافی در درایورها استفاده میکند.
با اینکه رهگیری پرتو برای انجام کارهای روزمره قابلیت مهمی محسوب نمیشود، نقش مهمی برای گیمرها ایفا میکند و وجود هستههای RT میتوانند موهبت بزرگی برای آنها محسوب شود؛ هرچند پردازندهی گرافیکی هاپر H100 مانند GA100، به سختافزاری برای رهگیری پرتو مجهز نیست.
علاوهبراین نسخههای مختلف پردازندههای گرافیکی Ada برای پلتفرمهایی که الگوریتمهای هوش مصنوعی و یادگیری ماشینی انجام میدهند، استفاده خواهند شد. پس به احتمال زیاد تعداد هستههای تنسور زیادی در این پردازندههای گرافیکی وجود خواهد داشت.
در کل میتوان گفت که تعداد ۱۴۴ واحد محاسباتی برای معماری Ada، آنچنان هم دور از ذهن به نظر نمیرسد.
سابسیستم حافظه: احتمال استفاده از GDDR6X در معماری Ada
حافظهی GDDR6X، حافظهی دسترسی همزمان و پویا با پهنای باند بالا و تقریباً برابر با نرخ دوبرابری دادهها محسوب میشود که توسط مایکرون و برای کارت گرافیک کنسول بازی ویدئویی تولید شده است. این حافظه از تکنیکهای سیگنالدهی چندسطحی استفاده میکند و به ادعای مایکرون، تنها تولید کنندهی آن، توانایی دستیابی به پهنای باند بالایی را بهازای هر تراشه دارد.
مایکرون چندی پیش اعلام کرد که در نظر دارد دسترسی به سرعت ۲۴ گیگابیتبرثانیه را برای حافظهی GDDR6X فراهم کند. سرعت این حافظه برای گرافیک RTX 3090 Ti، برابر با ۲۱ گیگابیتبرثانیه بود و ازآنجاکه انویدیا برای تمام محصولاتش از GDDR6X استفاده میکند، به نظر میرسد که سرعت جدید این حافظه به معماری Ada انویدیا مربوط باشد؛ پردازندههای گرافیکی ردهپایینتر انویدیا که حداکثر سرعت حافظهی آنها ۱۸ گیگابیتبرثانیه است، به جای حافظهی GDDR6X از حافظهی GDDR6 معمولی استفاده میکنند.

پردازندهی گرافیکی GA102 معماری Ampere از دوازده رابط حافظهی ۳۲ بیتی با GDDR6X پشتیبانی میکند؛ گمان میرود AD102 نیز از طرحبندی مشابهی بهعلاوه سرعت بیشتر حافظه استفاده کند.
این افزایش سرعت حافظه میتواند مشکل ایجاد کند، چراکه در پردازندههای گرافیکی برای تحقق میزان عملکرد وعده دادهشده معمولاً باید دو عامل محاسبات و پهنای باند باهم تناسب داشته باشند. برای مثال گرافیک RTX 3090 Ti از مدل 3090 حدود ۱۲ درصد محاسبات بیشتری انجام میدهد و ۸ درصد پهنای باند بیشتری فراهم میکند. اگر برآوردهای محاسباتی اشارهشده بالا درست باشند، گرافیک RTX 4090 فرضی حدود ۸۰ درصد محاسبات بیشتری نسبت به گرافیک RTX 3090 Ti خواهد داشت، درحالیکه پهنای باند تنها ۱۴ درصد افزایش پیدا میکند؛ چنین عدم تناسبی باعث میشود ارتباط محاسبات و پهنای باند قطع شود.
درحالحاضر گرافیکهای RTX 3050 تا RTX 3070 همگی از حافظهی استاندارد GDDR6 با سرعت ۱۴ تا ۱۵ گیگابیتبرثانیه استفاده میکنند و ازآنجاکه این حافظهی استاندارد میتواند با سرعتی برابر با ۱۸ گیگابیتبرثانیه برای معماری Ada استفاده شود، چنین سرعتی در گرافیک RTX 4050 فرضی نیز بهراحتی میتواند قدرت محاسباتی پردازندهی گرافیکی را افزایش دهد. در پردازندههای پایینردهی انویدیا با فرض کنترل مصرف برق GDDR6X، امکان افزایش پهنای باند وجود دارد، بنابراین چنانچه انویدیا همچنان به پهنای باند بیشتری نیاز داشت، میتواند از حافطهی ارتقایافتهی GDDR6X برای پردازندههای گرافیکی سطحپایینتر استفاده کند.
احتمال کمی نیز وجود دارد که پردازندههای گرافیکی بالاردهی Ada با حافظهی GDDR7 یا شاید GDDR6+ سامسونگ با سرعتی برابر ۲۷ گیگابیتبرثانیه همراه شوند، اما با توجه به اینکه هنوز هیچ اطلاعاتی در مورد حافظهی GDDR7 یا GDDR6+ در دست نیست، این احتمال را فعلاً نادیده میگیریم.
استفاده از حافظهی کش L2 قابلتوجه
یکی از بهترین روشها برای کاهش نیاز به پهنای باند بالا، افزایش حافظهی کش روی تراشه است. استفاده از سیستم کش به پردازندهی گرافیکی کمک میکند تا بیت بعدی از اطلاعات مورد نیازش را بلافاصله بعد از جستوجو پیدا کند؛ به این وضعیت Cache Hit میگویند. حافظهی کش بیشتر باعث میشود Cache Hit افزایش یابد و اینگونه دیگر پردازندهی گرافیکی به برداشت اطلاعات از حافظهی GDDR6 یا GDDR6X نیازی نخواهد داشت. اینفینیتی کش AMD به همین منوال به تراشههای RDNA 2 اجازه میدهد وظایف بیشتری را با پهنای باند کمتری انجام دهند و حالا اطلاعات فاششده از معماری Ada انویدیا و حافظهی کش L2 نشان میدهد که تیم سبز قصد دارد رویکردی مشابه تیم قرمز در پیش بگیرد.
ایامدی درپردازندهی گرافیکی Navi 21 از حافظهی کش L3 تا ۱۲۸ مگابایت استفاده میکند. این حافظه در پردازندهی گرافیکی Navi 22 برابر با ۹۶ مگابایت، در Navi 23 برابر با ۳۲ مگابایت و در Navi 24 برابر با ۱۶ مگابایت است. حتی کمترین ظرفیت حافظهی کش L3 در میان این ۴ ظرفیت برای سابسیستم حافظه به خوبی عمل میکند.
برای مثال انتظار نمیرفت کارت گرافیک Radeon RX 6500 XT با پردازندهی گرافیکی Navi 24، کارت گرافیک قدرتمندی باشد، اما این محصول پایینرده با وجود ۱۶ مگابایت حافظهی کش L3 توانست با کارتهای گرافیکی تقریباً با دو برابر پهنای باند حافظه، رقابت کند.
براساس گزارشهای منتشرشده، در معماری Ada هر کنترلر حافظهی ۳۲ بیتی با یک حافظهی کش ۸ مگابایتی L2 همراه است؛ با این کار، کارتهای گرافیکی که رابط حافظهای ۱۲۸ بیتی دارند، ۳۲ مگابایت حافظهی کش L2 خواهند داشت و کارتهای گرافیکی با ۳۸۴ بیت رابط حافظه، به ۹۶ مگابایت حافظهی کش L2 مجهز خواهند بود. البته ازآنجاکه این مقادیر از اینفینیتی کش ایامدی کمتر هستند، هنوز تأخیر در عملکرد آنها را نمیتوان بهدرستی پیشبینی کرد.
درکل حافظهی کش L2 نسبت به کش L3 تأخیر کمتری دارد، بنابراین حافظهی کش L2 با ظرفیت کمی کمتر، قطعاً میتواند با حافظهی کش L3 با ظرفیت بیشتر اما کندتر رقابت کند.
برای مثال، گرافیک RX 6700 XT ایامدی نسبت به گرافیک نسل قبلی خود، یعنی RX 5700 XT، حدود ۳۵ درصد محاسبات بیشتری انجام میدهد. از طرف دیگر بنچمارکها نشان میدهند که این پردازندهی گرافیکی در رزولوشن 1440p اولترا نیز حدود ۳۲ درصد بهتر عمل میکند و عملکرد کلی تقریباً با بهبود محاسبات همخوانی دارد. باید توجه داشت که گرافیک 6700 XT به رابط حافظهی ۱۹۲ بیتی و تنها ۳۸۴ گیگابایتبرثانیه پهنای باند مجهز بوده که از پهنای باند ۴۴۸ گیگابایتبرثانیهای RX 5700 XT حدود ۱۴ درصد کمتر است. پس میتوان اینگونه نتیجه گرفت که اینفینیتی کش L3 ایامدی ۵۰ درصد افزایش پهنای باند مؤثر را به ارمغان میآورد.
با فرض اینکه انویدیا بتواند با معماری Ada نتایج مشابهی را فراهم کند، افزایش ۱۴ درصدی پهنای باندی که ازطریق حافظهی ۲۴ گیگابیتبرثانیه ارائه میشود در ترکیب با افزایش ۵۰ درصدی در پهنای باند مؤثر باعث خواهد شد AD102 تقریباً ۷۱ درصد پهنای باند مؤثرتری ارائه کند که افزایش محاسبات پردازندهی گرافیکی را به همراه دارد.
انویدیا در مورد پردازندهی گرافیکی هاپر H100 جزئیات زیادی به اشتراک گذاشته و ظرفیت بیشتر حافظهی کش L2 نسبت به نسل قبلی، یعنی GA100 را تأیید کرده، اما در این محصول بهازای هر رابط حافظه، دیگر ۸ مگابایت حافظهی کش مگابایتی L2 در نظر گرفته نشده است. در واقع، کل حافظهی کش L2 هاپر H100 به ۵۰ مگابایت میرسد؛ این مقدار در A100 برابر با ۴۰ مگابایت بود. هاپر همچنین از حافظهی HBM3 نیز استفاده میکند و ۸۰ گیگابایت حافظهی گرافیکی دارد.
مصرف برق در معماری Ada
مصرف برق در معماری Ada، به احتمال زیاد باعث تعجب همگان خواهد شد. اولین شایعاتی که درمورد مصرف برق معماری Ada منتشر شدند به مصرف ۶۰۰ واتی اشاره داشتند؛ آن زمان باور این حجم از مصرف برای همهی کاربران عجیب بود.
برق مصرفی کارتهای گرافیکی انویدیا برای سالهای متمادی، نزدیک به ۲۵۰ وات بود؛ در معماری Ampere این مقدار در کارت گرافیک RTX 3090 (و بعدتر برای کارت گرافیک RTX 3080 Ti) به ۳۵۰ وات افزایش یافت که بیش از حد زیاد به نظر میرسید. زمانی که انویدیا مشخصات پردازندهی گرافیکی هاپر H100 را اعلام و کارت گرافیکی RTX 3090 Ti را عرضه کرد، باور ۶۰۰ وات مصرف برق دیگر آنچنان دور از ذهن نبود.

کارت گرافیک RTX 3090 Ti درحالحاضر ۵۰۰ وات یا بیشتر برق مصرف میکند.
مقیاسبندی دنارد (Dennard) یا مقیاسبندی ماسفت (MOSFET) قانونی در مقیاسبندی است که بهطور تقریبی بیان میکند با کوچکتر شدن ترانزیستورها، چگالی توان آنها ثابت میماند و مصرف توان نیز با مساحت ترانزیستورها متناسب است. قانون مور نیز بیان میکند که تعداد اجزای هر مدار مجتمع در یک دورهی زمانی قابلپیشبینی بهطور مرتب دوبرابر خواهد شد؛ این بازهی زمانی در ابتدا ۱۲ ماه در نظر گرفته شده بود، اما بعدها گسترش یافت و به ۲۴ ماه رسید.
به زبان ساده، مقیاسبندی دنارد (یا همان ماسفت) نشان میدهد که با هر نسل، ابعاد را میتوان تا حدود ۳۰ درصد کاهش داد. با این کاهش ابعاد، مساحت کلی تا ۵۰ درصد، ولتاژ تا ۳۰ درصد و تأخیر در مدار نیز ۳۰ درصد کاهش مییابد. علاوهبراین، فرکانسها حدود ۴۰ درصد افزایش پیدا میکنند و مصرف برق کلی نصف میشود؛ شاید این تغییرات روی کاغذ بیش از حد خوب به نظر برسند، اما واقعیت این است که مقیاسبندی دنارد ۱۵ سال پیش و در سال ۲۰۰۷ نقض شد.
همین موضوع درمورد قانون مور نیز صدق میکند، البته قانون مور بهطور کامل نقض نشده، اما تفاوتهای فاحشی در دستاوردها و قانون مذکور به چشم میخورد.
از سال ۲۰۰۴ تا به امروز، حداکثر فرکانس مدارهای مجتمع از ۳٫۷ گیگاهرتز به ۵٫۵ گیگاهرتز در Core i9-12900KS افزایش یافته است که تقریباً ۵۰ درصد افزایش در طول شش نسل بهبود لیتوگرافی محسوب میشود. به عبارت دیگر، اگر مقیاسبندی دنارد نقض نشده بود، پردازندههای امروزی باید به فرکانسی تا ۲۸ گیگاهرتز نیز میرسیدند.
این موضوع به فرکانس محدود نمیشود و قدرت و ولتاژ نیز در این مقیاسبندی تغییر میکنند. امروزه، لیتوگرافیهای جدید میتوانند چگالی ترانزیستور را بهبود بخشند، اما لازم است تا ولتاژها و فرکانسها نیز متعادل شوند.
انویدیا دو رویکرد در پیش رو داشت:
- تولید تراشهای با سرعت دو برابر که به قیمت مصرف برقی تقریباً دو برابری تمام شود.
- تولید تراشهای با مصرف برقی بهینهتر که سرعت پایینتری داشته باشد.
براساس گزارشهای منتشرشده به نظر میرسد انویدیا در معماری Ada، رویکرد اول را انتخاب کرده است:
اگر از پردازندهی گرافیکی ۳۵۰ واتی معماری Ampere مانند GA102 استفاده کنید و عملکرد را بین ۷۰ تا ۸۰ درصد افزایش دهید، ۷۰ تا ۸۰ درصد برق بیشتری مصرف خواهید کرد. حال فرض کنید که این ۳۵۰ وات به عددی بین ۵۹۵ تا ۶۳۰ وات برسد؛ البته به احتمال زیاد انویدیا تمام تلاش خود را برای به حداقل رساندن مصرف برق میکند و مصرف برق ۶۰۰ واتی که در شایعات مطرح شده، حداکثر توان مصرفی در کارتهای رفرنس خواهد بود.
نامگذاری کارت گرافیکهای مبتنی بر معماری Ada
با توجه به الگوی نامگذاری تیم سبز و سرمایهگذاری این شرکت روی برند RTX، پیشبینی نام RTX 40 برای نسل جدید گرافیکهای انویدیا کاملاً معقول به نظر میرسد، اما بازهم ممکن است کارت گرافیکهایی مبتنی بر معماری Ada با نامگذاری متفاوتی عرضه شوند.
در نهایت این محصولات با هر نامی که عرضه شوند، همان عملکرد قدرتمند و قابلیتهای چشمگیر را ارائه کرده و میتوانند کاربران را شگفتزده کنند.
قیمتگذاری کارتهای گرافیک مبتنی بر معماری Ada
واقعیت این است که انویدیا هم مانند هر برند دیگری میخواهد تا جایی که بازار کشش داشته باشد، از کارتهای گرافیکی نسل بعدی خود کسب درآمد کند. این شرکت در زمان عرضهی کارتهای گرافیک مبتنی بر معماری Ampere مدلی برای قیمتگذاری در نظر گرفت که بعدها ثابت شد برای دوران همهگیری کووید کاملاً اشتباه بود.
قیمتها در دنیای واقعی افزایش یافت و اسکالپرها نیز سودجویی کردند؛ این اوضاع با دخالت استخراجکنندگان ارزهای دیجیتال وخیمتر شد و قیمتها بازهم بالاتر رفت. کارتهای گرافیک مورد اشاره درحالحاضر تقریباً ۳۰ درصد گرانتر از قیمتگذاری انویدیا در بازار به فروش میرسند.

قیمت کارتهای گرافیکی مبتنی بر معماری Ada به احتمال زیاد بازهم افزایش خواهد یافت. درواقع افزایش حجم حافظهی کش L2 و افزایش نسبتاً محدود پهنای باند حافظه در معماری Ada، عملکرد ماینینگ را نسبت به معماری Ampere کمی افزایش میدهد. کارتهای گرافیک مبتنی بر معماری RDNA 2 ایامدی نیز کمی سریعتر از مدلهای مبتنی بر RDNA هستند و این بدان معنا است که ماینینگ به تنهایی نمیتواند دلیل بالا رفتن قیمتها باشد.
بسته به نرخ عرضه و تقاضا در زمان عرضهی کارتهای گرافیک Ada، ممکن است نسخهی پرچمدار این سری یعنی AD102 با قیمت پایهی ۹۹۹ دلار (احتمالاً برای RTX 4080) عرضه شود و قدرتمندترین مدل آن نیز (احتمالاً RTX 4090) با قیمتی بالاتر از قیمت ۱٬۹۹۹ دلاری RTX 3090 Ti به فروش برسد.
حتی احتمال میرود انویدیا نام تجاری Titan را دوباره برای Ada احیا کند. درواقع دلیلی وجود ندارد که انویدیا بلافاصله معماری تمام تولیدات گرافیکی خود را از Ampere به Ada تغییر دهد و ازآنجاکه هیچ پردازنده یا پردازندهی گرافیکی دیگری خواهان استفاده از فرایند 8N فاندری سامسونگ نیست، احتمالاً برای مدتی طولانی همچنان شاهد معرفی پردازندههای گرافیکی بیشتری از سری RTX 30 خواهیم بود.
انویدیا احتمالاً با معرفی کارتهای گرافیک پیشرفته Ada و استفاده از تمام ظرفیتی که میتواند از TSMC دریافت کند، سود بیشتری به دست خواهد آورد و در این راه ممکن است حتی قیمت کارتهای گرافیک سری RTX 30 موجود را نیز کاهش دهد.
اطلاعات مربوط به قیمتگذاری معمولاً از آخرین فاکتورهایی است که در مورد هر محصول به بیرون درز پیدا میکند؛ بنابراین تا به این لحظه هنوز نمیتوان با اطمینان مدل قیمتگذاری این محصولات را پیشبینی کرد.
تغییرات در طراحی Founders Edition کارتهای گرافیک Ada
انویدیا هنگام معرفی گرافیکهای RTX 3080 و RTX 3090 ادعاهای زیادی در مورد طراحی نسخهی Founders Edition این دو محصول مطرح کرده بود. نسخهی Founders Ediotion این دو محصول عملکرد مناسبی ارائه میکند، اما تجربیات ۱۸ ماه گذشته نشان میدهند که برخی کارتهای شخص ثالث سیستم خنککنندهی بهتری دارند و بیصداتر کار میکنند. نسخهی Founders Edition کارت گرافیک RTX 3080 Ti نمونهای آشکار برای اثبات این امر است که دما و سرعت فن نمیتوانند با پردازندههای گرافیکی در حال اجرا با دمای بالا، سازگاری داشته باشند.

گرافیک RTX 3080 انویدیا؛ متفاوت با تمام کارت گرافیکهای قبلی
با توجه به مصرف برق شایعهشدهی معماری Ada و دو برابر بودن آن نسبت به معماری Ampere، احتمال پایبند ماندن تیم سبز به طراحی صنعتی فعلی پایین است. هنوز اطلاعاتی درمورد طراحی نسخههای Founders Edition انویدیا برای گرافیکهای Ada در دست نیست، اما ازآنجاکه همهی کارتهای گرافیک سه یا بیشتر اسلات را اشغال میکنند، این شرکت برای از بین بردن گرمای حاصل از مصرف برق ۶۰۰ واتی، باید به فکر خنککنندهای اکسترنال باشد.
زمان عرضهی پردازندههای گرافیکی Ada
تابهحال بارها به بازهی زمانی سپتامبر تا اکتبر برای عرضهی پردازندههای گرافیکی Ada و سری RTX 40 اشاره شده است، اما باید به خاطر داشت که اولین کارتهای گرافیک Ada که معرفی میشوند، تنها شروعی برای عرضهی کارتهای گرافیک از این سری خواهند بود. انویدیا دو گرافیک RTX 3080 و RTX 3090 را سپتامبر ۲۰۲۰ (شهریور ۱۳۹۹) عرضه کرد، گرافیک RTX 3070 یک ماه بعد و سپس گرافیک RTX 3060 Ti ماه بعد از آن در بازار به فروش رسید. تیم سبز گرافیک RTX 3060 را به همراه گرافیک RTX 3080 Ti و RTX 3070 Ti در ژوئن ۲۰۲۱ (خرداد ۱۴۰۰)، گرافیک RTX 3050 مقرونبهصرفه را ژانویه ۲۰۲۲ (دی ۱۴۰۰) و در نهایت RTX 3090 Ti را پایان مارس ۲۰۲۲ (فروردین ۱۴۰۱) عرضه کرد.
انتظار میرود روال عرضهی کارتهای گرافیک Ada مشابه گرافیکهای Amepere، با عرضهی سریعترین مدلها شروع شده و با فروش مدلهای پرچمدار ادامه پیدا کند.
به احتمال زیاد تقریباً یک سال پس از عرضهی اولیه نیز، یک بهروزرسانی در گرافیکهای Ada خواهیم داشت، اما هنوز مشخص نیست که این بهروزرسانیها در قالب چه نامهایی (Ti یا Super یا…) معرفی خواهد شد.
رقابت بیشتر در فضای پردازندههای گرافیکی
چندین دهه است که انویدیا یکی از برندهای مطرح در صنعت کارتهای گرافیک محسوب میشود؛ تیم سبز تقریباً ۸۰ تا ۹۰ درصد از کل بازار گرافیک را در دست دارد و تا حد زیادی هم برای ایجاد و پذیرش فناوریهای جدید مانند رهگیری پرتو و DLSS تلاش کرده است. بااینحال، با افزایش اهمیت کاربرد هوش مصنوعی و محاسبات برای تحقیقات علمی و سایر کارهای محاسباتی و اتکای آنها به پردازندههایی مشابه پردازندههای گرافیکی، شرکتهای دیگری مانند اینتل نیز بهتازگی به این حوزه ورود کردند.
اینتل از اواخر دههی ۹۰ برای مدتی طولانی دیگر کارت گرافیک اختصاصی تولید نکرد و به نظر میرسید که بیشتر بر قابلیتهای رسانهای تمرکز کرده باشد. مدلهای مصرفی برتر گرافیکهای این شرکت در بهترین حالت قدرت انجام محاسبات ممیز شناور تکدقتی برابر با ۱۸ ترافلاپس داشتند که طبق جدول ابتدای مقاله تنها میتوانند رقیبی برای پردازندهی AD106 محسوب شوند.
بااینحال طبق گزارشهای منتشرشده، اینتل قصد دارد بهزودی دوباره به عرصه وارد شود و با معرفی نسل دوم معماری Arc Alchemist، با نام Battlemag تواناییهای Alchemist را دو برابر کرده و سهم بازار انویدیا را بهویژه در فضای لپتاپهای گیمینگ تصاحب کند.
ایامدی نیز به سهم خود برای دستیابی به جایگاهی در این صنعت تلاش میکند و تابهحال چندین بار دربارهی برنامهی خود برای معرفی معماری RDNA 3 تا پایان سال جاری، بیانیههایی مطرح کرده است. انتظار میرود تیم قرمز در نسل بعدی معماری خود از گرهی TSMC N5 استفاده کند و بتواند مستقیماً در حوزهی ویفرها با انویدیا وارد رقابت شود. این شرکت تابهحال از قرار دادن هرگونه سختافزار مخصوص یادگیری عمیق در پردازندههای گرافیکی مصرفکنندهی خود اجتناب کرده، اما با توجه به اینکه اینتل در معماری Arc از هستههای Xe Matrix استفاده میکند، احتمال دارد ایامدی نیز رویکرد خود را در اینباره تغییر دهد؛ هستههای Xe Matrix، به فناوری XeSS مجهز هستند که قابلیتهایی برای بهبود هوش مجازی دراختیار میگذارند.
در انتها باید گفت شکی وجود ندارد که انویدیا درحالحاضر عملکرد رهگیری پرتوی بسیار چشمگیرتری نسبت به کارتهای سری RX 6000 ایامدی ارائه میکند؛ تیم قرمز در مورد سختافزار رهگیری پرتو یا نیاز به افکتهای آن در بازیها، هنوز حرفی برای گفتن ندارد و اینتل نیز به نوبهی خود ممکن است عملکرد رهگیری پرتوی ضعیفتری نسبت به ایامدی ارائه دهد.
درواقع تا زمانی که بیشتر بازیها سریع اجرا شوند و به جلوههای رهگیری پرتو نیازی نداشته باشند، بهراحتی نمیتوان مردم را متقاعد کرد که کارتهای گرافیک خود را ارتقا دهند؛ اما میتوان امیدوار بود که بعد از دو سال طولانی کمبود و گرانی پردازندههای گرافیکی و کارتهای گرافیکی پرچمدار، سرانجام در سال پیش رو این مشکلات رفع شده و صنعت پردازندههای گرافیکی دوباره به صنعتی مطرح تبدیل شود.
