هوش مصنوعی با خواندن مغز افراد، چهرههای ساختگی جذابی خلق میکند

در چند سال اخیر، هوش مصنوعی توانسته است بسیاری از تواناییهای انسانی، از جمله خواندن، نوشتن، دیدن، لمس کردن، درک کردن، خلق کردن و بازی کردن را به طرز شگفتانگیزی حتی بهتر از انسان انجام بدهد؛ اما با تمام این پیشرفتها، این تکنولوژی هنوز نتوانسته است در مناظرهی رسمی با انسان عملکرد قابل قبولی داشته باشد.
برای غلبه بر این مشکل، IBM که چندی پیش برای کمک به مطالعات دربارهی ویروس کرونای جدید، هوش مصنوعیاش را در اختیار دانشمندان گذاشت، پروژهی Debater را راهاندازی کرده است تا نشان بدهد هوش مصنوعی میتواند حتی از پس مناظره با انسان دربارهی موضوعات پیچیده برآید.
بسیاری از پروژههای هوش مصنوعی، مخصوصا آنهایی که بر بازی متمرکز هستند، به کمک ارزیابی معیارهای عددی، برنده و بازندهی مشخصی دارند؛ اما شرکت در مناظره با انسان به مهارت بسیار متفاوتی نیاز دارد. پروژهی Debater نشان داد هوش مصنوعی ساخت شرکت IBM نهتنها قادر است دربارهی موضوعی تحقیق کند، بلکه میتواند متناسب با موضوع بحث، دیدگاه جذاب و درگیرکنندهای مطرح کند و در رد دیدگاه حریف انسانی، از استدلال متقابل کمک بگیرد.
مقالههای مرتبط:
به گزارش Extremetech، مقالهی جدیدی در مجلهی Nature نتایج آزمایشی که در سال ۲۰۱۹ بین Project Debater و هریش ناتاراجان، قهرمان جهانی مناظره، برگزار شد، منتشر کرده است. در این آزمایش، هوش مصنوعی و انسان دربارهی اینکه آیا باید پیشدبستانی مشمول یارانه شود یا خیر با یکدیگر مناظره کردند. هر سمت مناظره ۱۵ دقیقه وقت داشت بدون دسترسی به اینترنت، خود را برای بحث آماده کند که Project Debater در این مدت، محتوای ذخیرهشده در دیتابیس داخلی خود را بررسی کرد. هر دو طرف چهار دقیقه دربارهی موضوع بحث صحبت کردند و دو دقیقه هم به جمعبندی اختصاص داشت.
از آنجایی که پروژهی Debater در نوع خود بینظیر است، محققان نمیتوانستند نتیجهی این آزمایش را با نمونههای پیشین مقایسه کنند؛ در نتیجه تصمیم گرفتند جملهی آغازین این پروژه را با جملات آغازینی که از روشهای دیگر به دست آمده بود، مقایسه کنند.
در نمودار زیر، Summit سیستم جمعبندی چندسندی، Speech-GPT2 «مدل زبانی بسیار دقیق» و Arg-GPT2 استدلالهایی است که از پیوند زنجیرهای ایجاد شده. Arg-Search به سخنرانیهایی اشاره میکند که از فناوری استخراج استدلال ArgumenText به دست آمدهاند. Arg-Human1 و Arg-Human2 به رویکردی ترکیبی اشاره دارند که در آن ماژول استخراج استدلال Debater را در مقابل نگارش و درستیسنجی انسانی میآزماید. آخرین ستون مربوط به سخنرانیهایی است که مستقیما از کارشناسان انسانی به دست آمده.
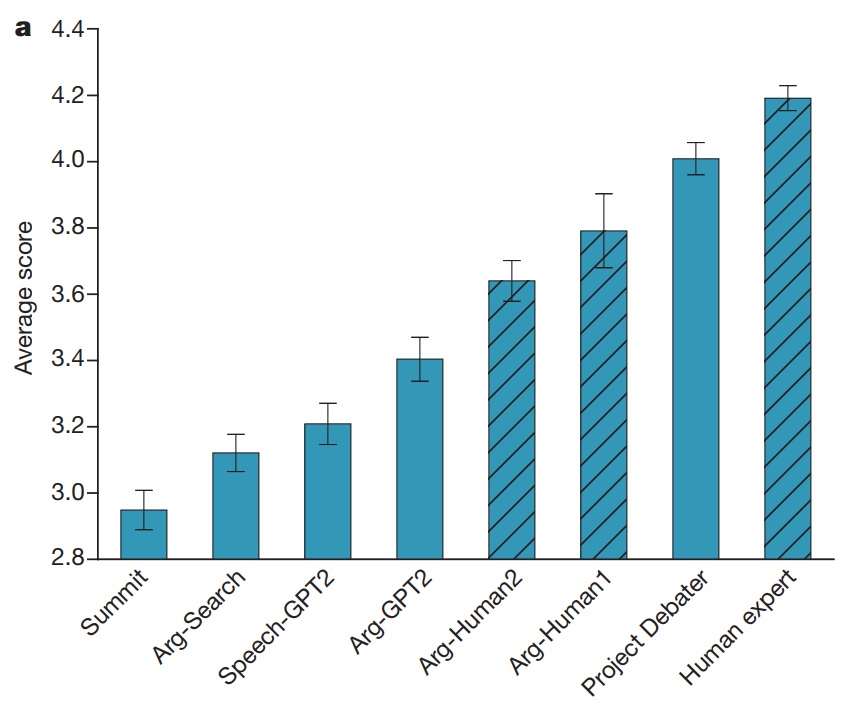
برای مقایسهی عملکرد هر یک از این موارد در مناظره، از خوانندگان خواسته شده بود به گزارهی «این جملهی آغازین خوبی برای این موضوع است»، از ۱ تا ۵ (بهشدت مخالف تا بهشدت موافق) نمره بدهند. از نظر خوانندگان، جملهای که هوش مصنوعی Debater برای شروع مناظره مطرح کرده بود، از نظر تناسب با موضوع بحث، فاصلهی چندانی با جملات کارشناسان انسانی نداشت.
این نمودار تنها قابلیت این پروژهی هوش مصنوعی را در طرح جملات آغازین مناظره ارزیابی میکند؛ اما در این حد نشان میدهد که این سیستم قادر است در مناظرات، استدلالهای منسجم و منطقی مطرح کند.
البته جواب این سؤال که برندهی مناظره کیست، همیشه برداشتی شخصی خواهد بود و حتی در این آزمایش هم انسانها عملکرد بهتری نسبت به پروژهی Debater داشتند؛ اما نمیتوان پیشرفت چشمگیر بشر را در حوزهی هوش مصنوعی، از زمان پروژهی پردازش زبان طبیعی Eliza (که توانست برای اولین بار تست تورینگ را با موفقیت پشت سر بگذارد) تا به امروز انکار کرد.
